 抓取网站数据代码实例下载
抓取网站数据代码实例下载
a806942026 LV2
2020年2月22日
项目描述疫情期间闲来无事,找个小项目练练手,该项目主要是爬取网易云音乐歌手下的所有专辑与音乐.有maven依赖运行环境jdk8+IntelliJ IDEA+maven项目技术(必填)jsoup是否原创(转载必填原文地址)原创项目截图(必填)运行截图(必填)注意事项(可选)1.java main方式运...

别让自己无聊 LV13
2019年6月18日
项目描述抓取豆瓣最评分最好的250部电影运行环境ubuntu+Python2.7项目技术(必填)Python数据库文件无jar包文件无是否原创(转载必填原文地址)非原创,项目截图(必填)运行截图(必填)注意事项需要导出在Windows上查看,Linux上编辑处于乱码...




洛庚 LV13
2014年7月22日
产生背景:公司有文员要从互联网上录入一些信息,效率低,费时费力,准确度不高。 我没事就做了个小小的demo ,设置相关参数,就可以快速抓取网站上的信息。流程(此 demo抓取对象是赶集):此信息展示列表的展示页的链接URL作为参数,首先抓取所有信息列表的链接,获得每条信息的链接后,依次打开链接,获得...
lgj123 LV9
2018年11月30日
项目描述python实现猫TV网站小爬虫运行环境python 3.0以上项目技术(必填)python数据库文件无jar包文件无是否原创(转载必填原文地址)转载项目截图(必填)运行截图(必填)注意事项无...


best2018 LV46
2022年3月1日
项目描述不错过最代码的任何一次牛币兑换活动!准确爬取最代码最新兑换活动,自动提醒,小伙伴们,行动起来吧!保持项目启动运行即可!运行环境jdk8+IntelliJ IDEA+maven项目技术(必填)springboot+jsoup+mybatis-plus依赖包文件(可选)项目jar包均通过mave...


hegang3 LV6
2018年12月18日
项目描述运用python语言编写,使用scrapy框架。专业数据爬取框架Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。运行环境pycharm python 项目技术(必填)python&nbs...

FlyHeLanMan LV11
2016年6月29日
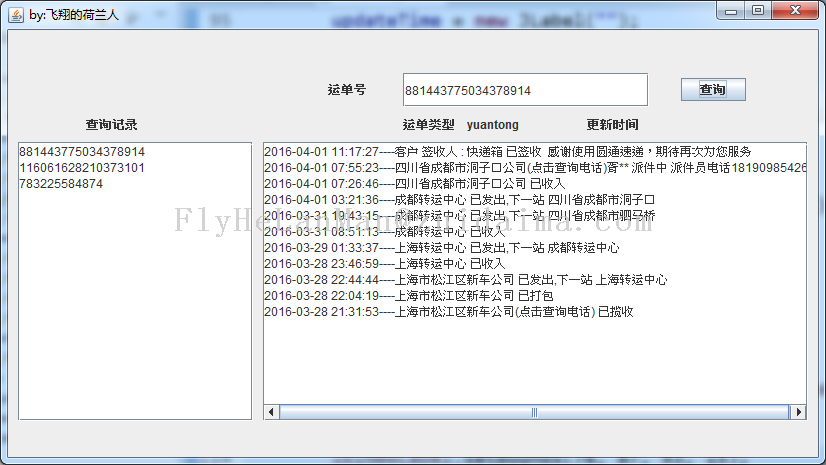
最近对swing挺感兴趣,做了个小工具练手查询接口是抓取的快递100的查询接口快递单号查询很简单的一个xiao东西,适合新手学习欢迎交流~以下是效果图: 做了下优化:增加了记录备注功能,如果已经存在备注则更新备注以下是效果图:有问题可以交流哦~代码已经更新重新打包上传~PS:不知道之前下载...

小白小怪 LV10
2021年6月19日
项目描述1.提取电影排名、名称、评分、评价人数、推荐语等信息;爬去每部电影的宣传图片分别以电影名命名放到命名为“海报”文件夹里。2.编写函数将第四步提取的信息写入文档;3.编写函数找出所有无推荐语的电影插入命名为’no_desc_movies’中。运行...



浪子逍遥遥 LV18
2015年4月23日
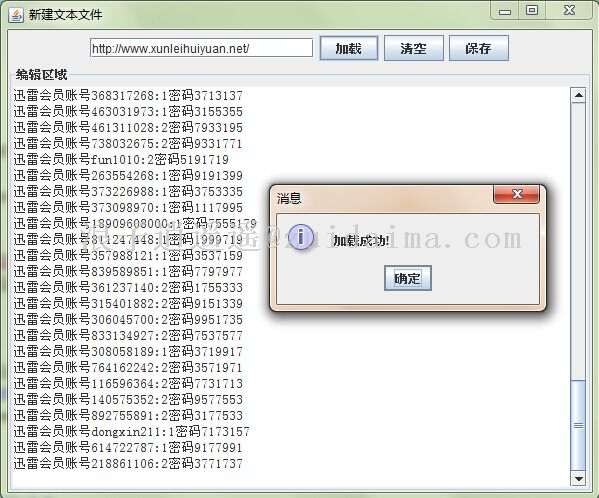
利用jsoup解析迅雷官网并提取迅雷VIP帐号与密码,这是一个学习的程序,所以不喜勿喷....

shengke LV17
2015年2月5日
看到牛哥分享了一个获取网页内容的例子,想到以前页写过类似的,目的是抓取网页上的内容,拿到后给自己的站点用。一般是通过正则表达式搞到自己想要内容,不知到有没有其他好的方法。本例子只是获取特定网站的源码。...

丶附耳聆听 LV21
2016年11月7日
前二天运营部的同事让我帮爬下数据,爬完了发出来大家分享。sql脚本代码都有。甩进去就能跑,快上车,滴,学生卡!...

码农_老王 LV10
2017年12月13日
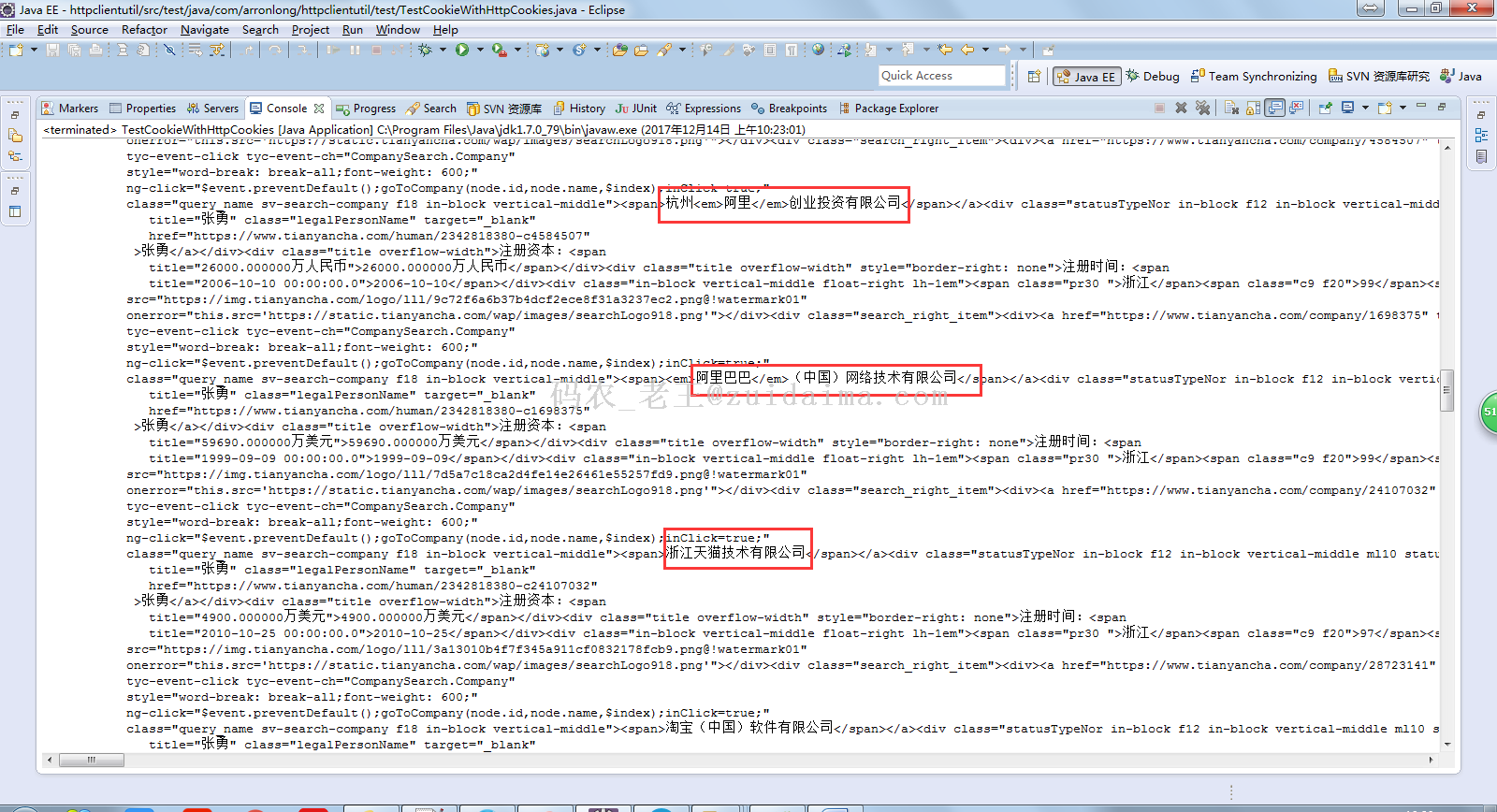
将HTTP简单话,对于喜欢研究爬虫的小伙伴有帮助。可实现文件下载,文件上传,可携带cookie进行请求爬取天眼查页面数据:...

charlesl LV2
2012年10月23日
爬虫简单示例,用httpClient4.2.1实现;连接池管理客户端请求,方便多线程使用。初学爬虫,望多提建议。同时,希望各位分享点爬虫相关的强大代码,以求学习,thx . 所需jar包上传至网盘类.由最代码官方编辑于2014-7-3 23:38:18...

X君 LV13
2013年5月31日
抓取网页中的电子邮件demo .由terryang编辑于2014-2-20 11:31:06...

lxw出山小草 LV5
2012年10月30日
获取指定网站的图片url,并下载由最代码官方编辑于2014-9-4 11:12:57...

Tonfay LV26
2013年6月19日
一个JAVA开发的简单网络爬虫 可以实现对指定站点新闻内容的获取 程序很简单 大家一起学习由最代码官方编辑于2014-1-24 18:22:49...

依然在路上 LV17
2016年7月1日
本项目使用了httpClient与jsoup两个技术,可以运用在项目中,在这里只是简单的测试,在真实的web项目中我们可以创建一个实体类,然后将获取到的数据保存到数据库中,比如我们需要大量的新闻进行展示,我们就可以才要该技术就行获取新闻保存到数据库中即可。...
已注销用户 LV34
2015年9月17日
{代码...}这两天发现一个新网站,无聊就去注册了一个账号。为了混个脸熟,写了一篇博客,写完后,习惯性的去浏览看看。然后发现一个小小的bug,阅读量变了,于是想到了最代码貌似没有这回事。最代码里面没有登录的时候去浏览文章或博客或分享的时候浏览量都不没有增加。所以无聊就写写代码,刷刷浏览量思路:用循环获取网页内容打...


何果财 LV3
2014年11月12日
分享的是一段较简单的爬虫,采用的网页分析方法是HTMLparser,抓取某个特定标签下的内容并存入excel表中。...
