 抓取网站数据代码实例下载
抓取网站数据代码实例下载
best2018 LV46
2022年3月1日
项目描述不错过最代码的任何一次牛币兑换活动!准确爬取最代码最新兑换活动,自动提醒,小伙伴们,行动起来吧!保持项目启动运行即可!运行环境jdk8+IntelliJ IDEA+maven项目技术(必填)springboot+jsoup+mybatis-plus依赖包文件(可选)项目jar包均通过mave...


小白小怪 LV10
2021年6月19日
项目描述1.提取电影排名、名称、评分、评价人数、推荐语等信息;爬去每部电影的宣传图片分别以电影名命名放到命名为“海报”文件夹里。2.编写函数将第四步提取的信息写入文档;3.编写函数找出所有无推荐语的电影插入命名为’no_desc_movies’中。运行...



socket LV6
2021年1月11日
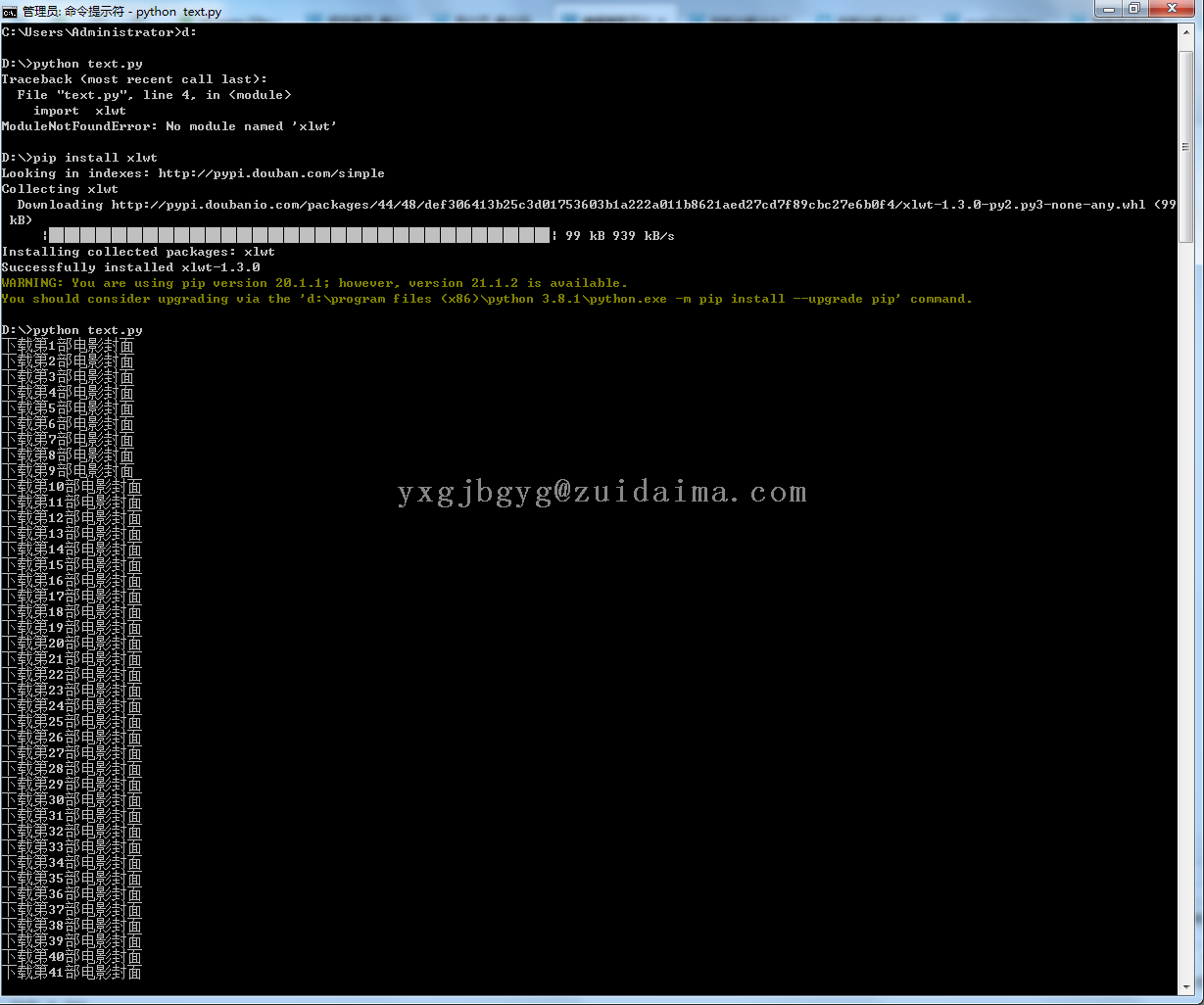
项目描述python爬取包括首页、搜索、分类、详情、章节目录、章节内容运行环境Python3.6+项目技术(必填)python第三方库requests,urllib,lxml依赖包文件pip install requestspip install urllib3pip install lxml是否原...


cuihui123 LV6
2020年7月4日
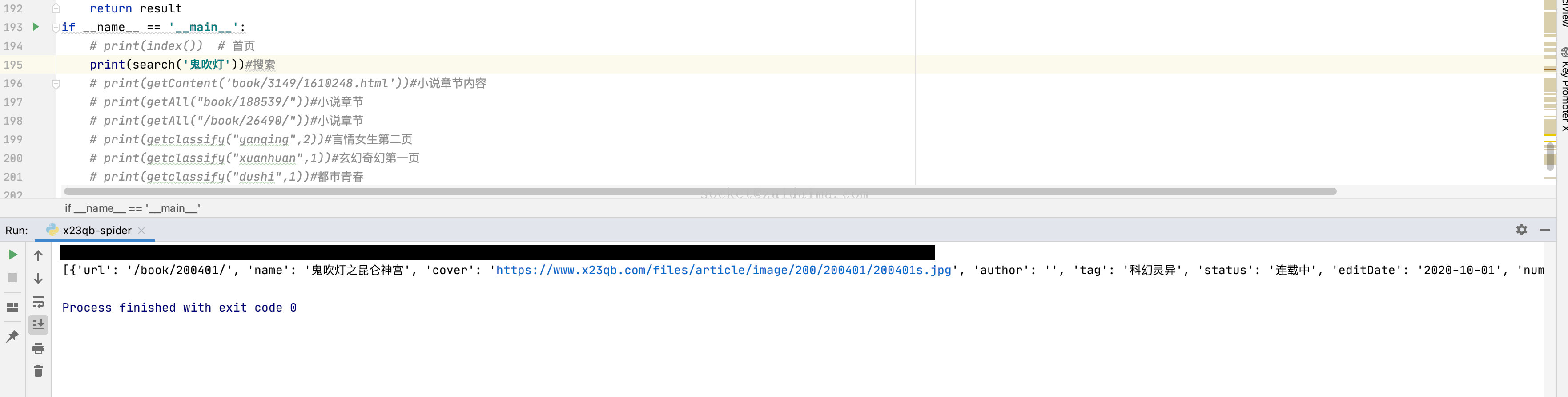
项目描述基础环境:python + flask + vue + element-ui + echartspython_spiders -- 爬虫后台项目python_spiders_web -- 爬虫前台项目运行环境python 3.8.3 + nginx + mysql项目技术(必填)Python...


随便取个名字_哈哈 LV27
2020年6月14日
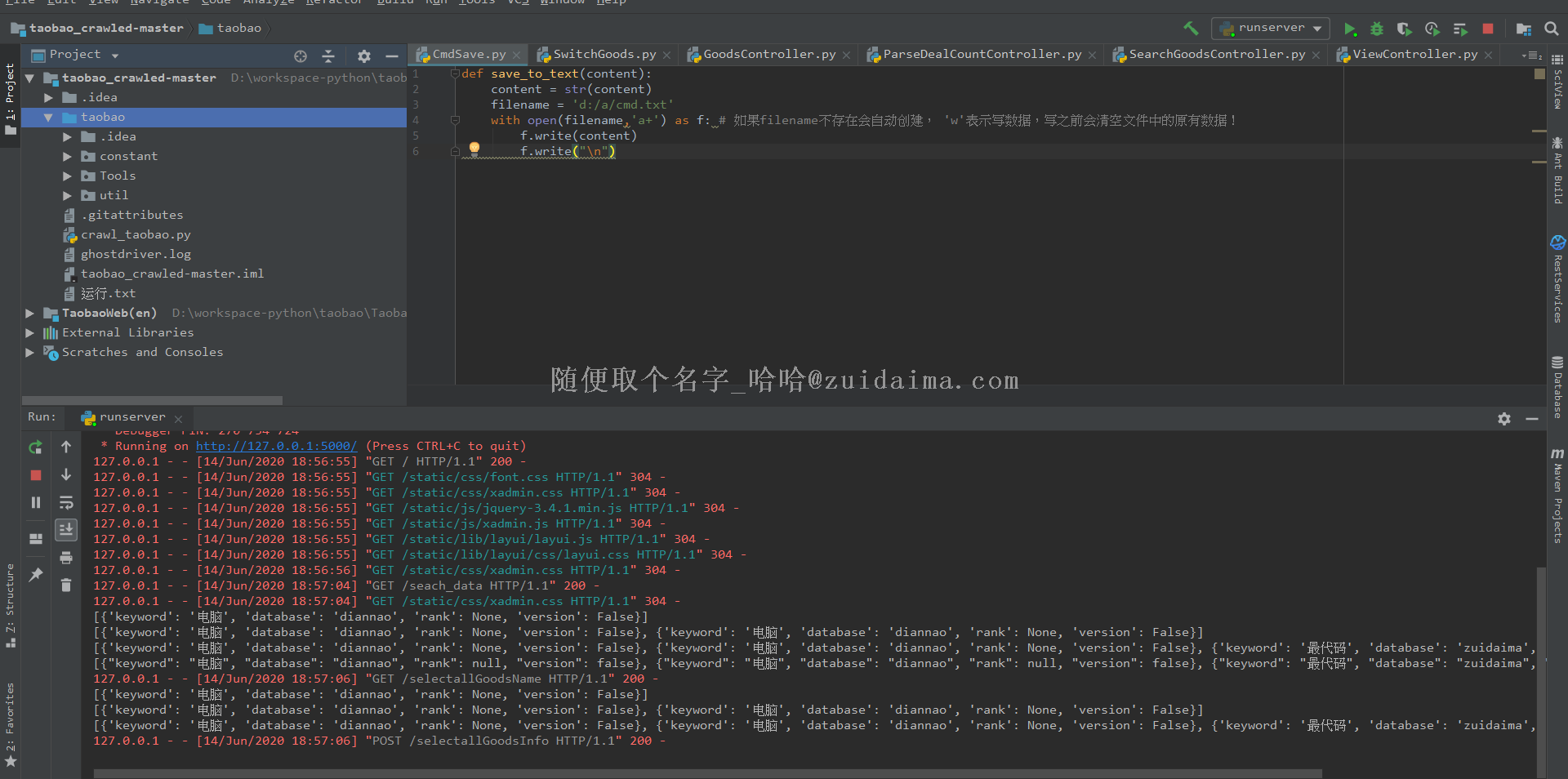
项目描述使用selenium、webdriver爬取淘宝的图片、商品、价格等信息。在命令行界面输入爬取的参数,把参数信息记录到txt文件中,运行爬虫程序后,先使用手机扫码登陆,然后pc端网页会自动翻淘宝的网页,知道翻到淘宝的最后一页,就会停止对商品的爬取web端功能:1.下拉框选择商品搜索2.点击图...

liuxuan123 LV1
2020年3月15日
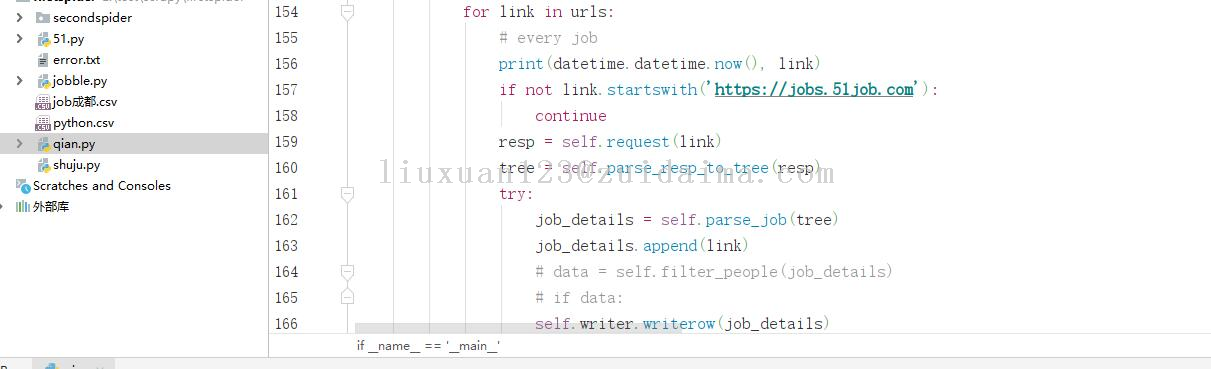
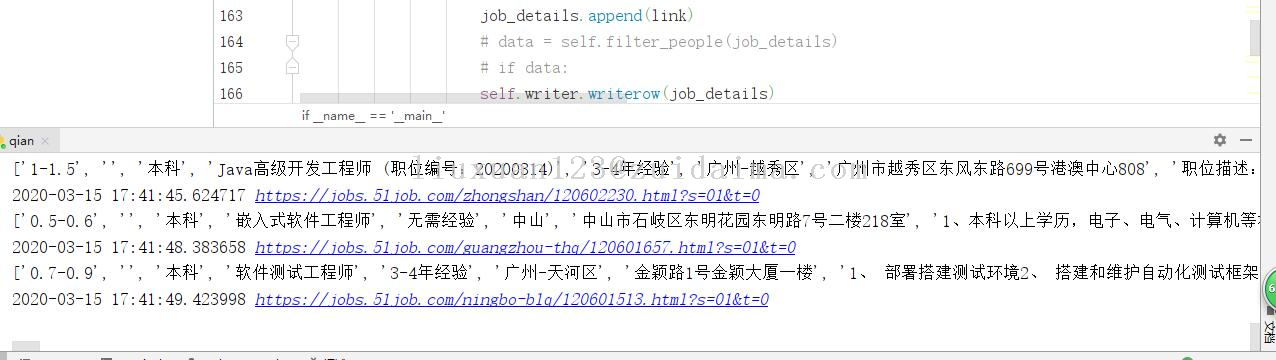
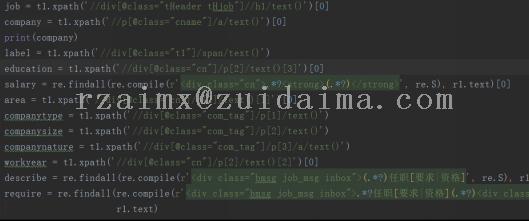
项目描述本项目数据来源于前程无忧,利用爬虫技术爬取前程无忧招聘信息,爬取的信息包括公司名称、职位名称、职位、薪水、工作经验、学历要求、工作地点、公司领域、公司规模;总共爬取了3000多条记录;运行环境python3.8+pycharm项目技术(必填)python爬虫依赖包文件(可选)需要安装如下框架...

a806942026 LV2
2020年2月22日
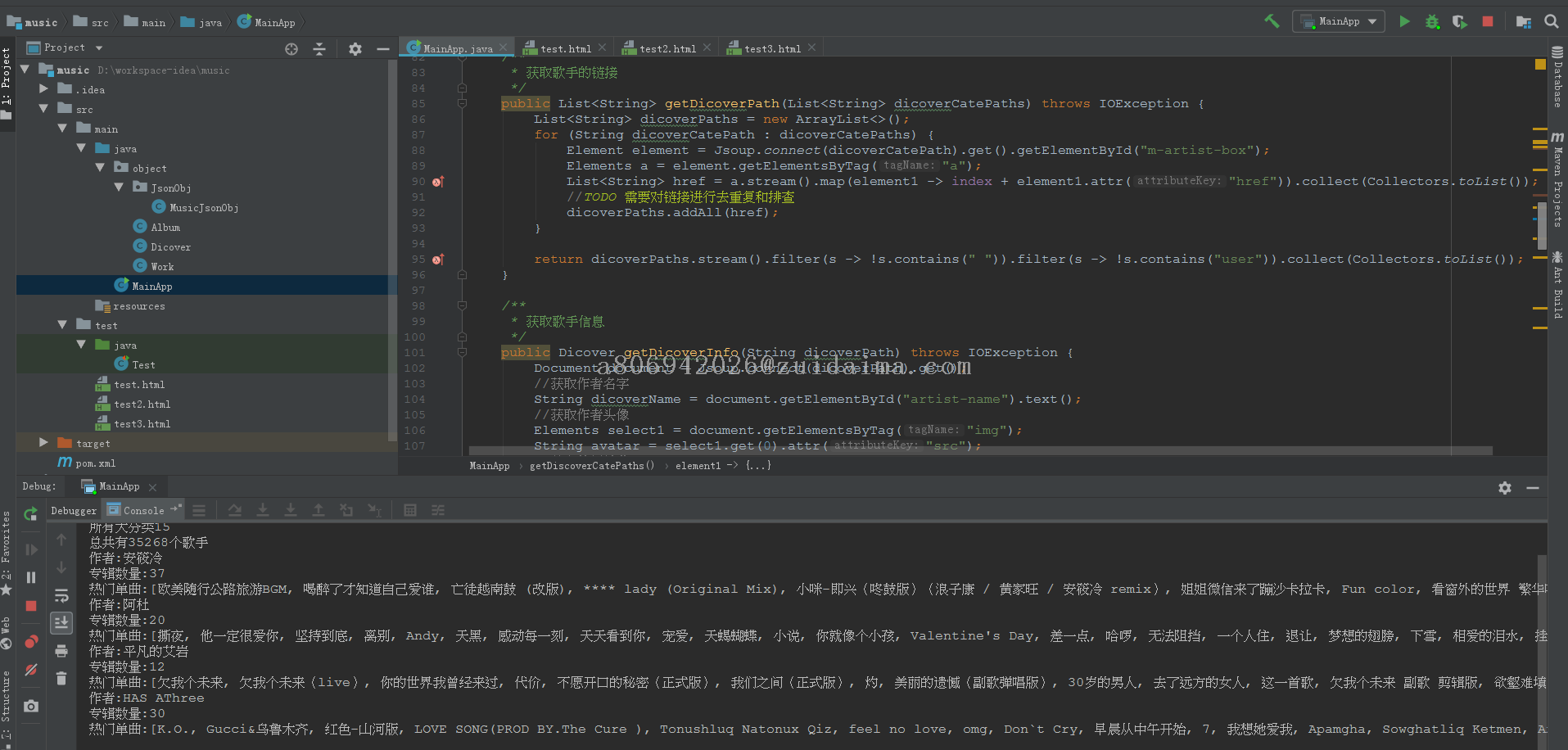
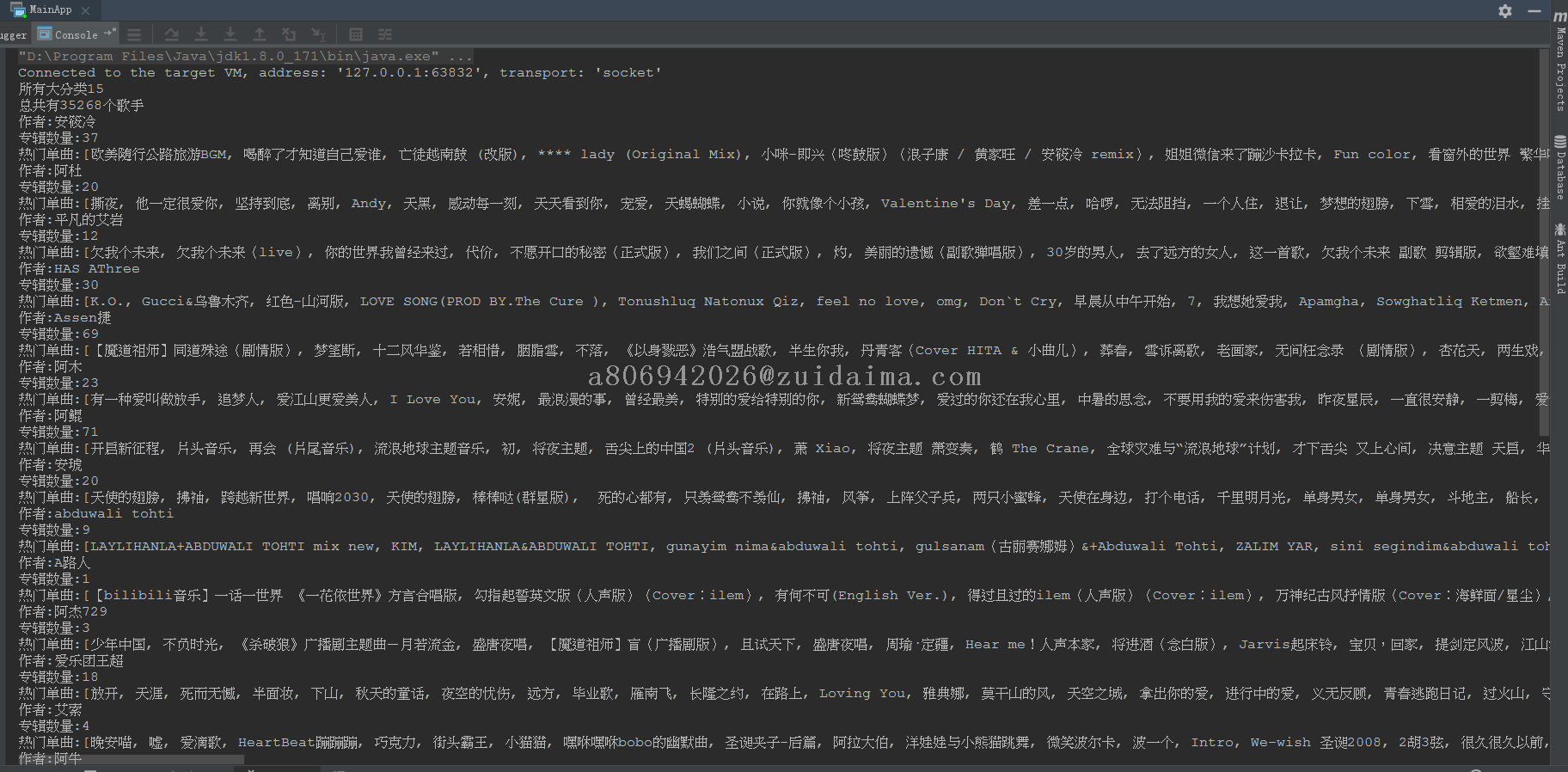
项目描述疫情期间闲来无事,找个小项目练练手,该项目主要是爬取网易云音乐歌手下的所有专辑与音乐.有maven依赖运行环境jdk8+IntelliJ IDEA+maven项目技术(必填)jsoup是否原创(转载必填原文地址)原创项目截图(必填)运行截图(必填)注意事项(可选)1.java main方式运...

别让自己无聊 LV13
2019年6月18日
项目描述抓取豆瓣最评分最好的250部电影运行环境ubuntu+Python2.7项目技术(必填)Python数据库文件无jar包文件无是否原创(转载必填原文地址)非原创,项目截图(必填)运行截图(必填)注意事项需要导出在Windows上查看,Linux上编辑处于乱码...



rzaimx LV3
2019年3月2日
{代码...}项目描述从前程无忧招聘网站上进行网页抓取,提取各项数据,数据包含多个维度,分别是城市、岗位名称、公司名字、公司规模、公司类型、经验要求、学历要求、专业要求、福利待遇和所属行业等。对爬取的数据进行数据清洗及标准化后,实现数据分析和可视化。最后实践apriori算法,进行频繁项集提取及关联分析。运行环境...


请叫我小C LV19
2019年2月12日
项目描述想不想免费下载一首某Q的付费音乐?代码中紧演示了mp3的下载,其余格式均已实现,需要自己调整代码,教你用代码免费下载,紧供学习,请勿用于商业。运行环境jdk7+eclipse+maven项目技术(必填)java数据库文件无项目截图(必填)运行截图(必填)...


hegang3 LV6
2018年12月18日
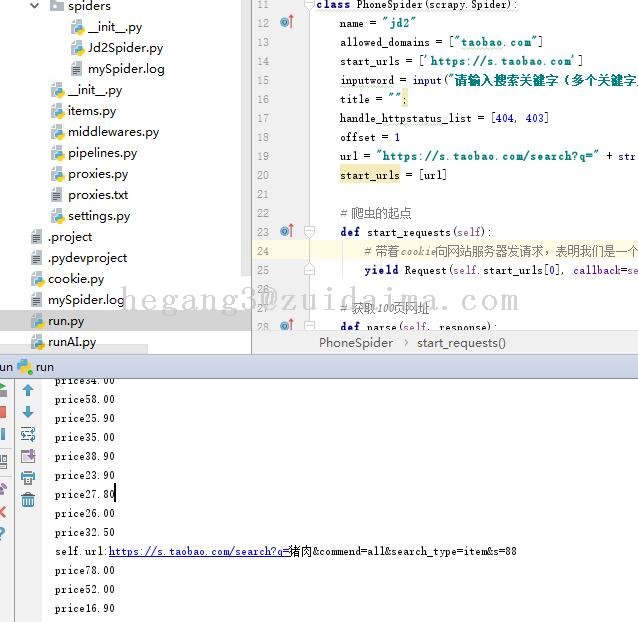
项目描述运用python语言编写,使用scrapy框架。专业数据爬取框架Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。运行环境pycharm python 项目技术(必填)python&nbs...

可人的小草 LV3
2018年12月10日
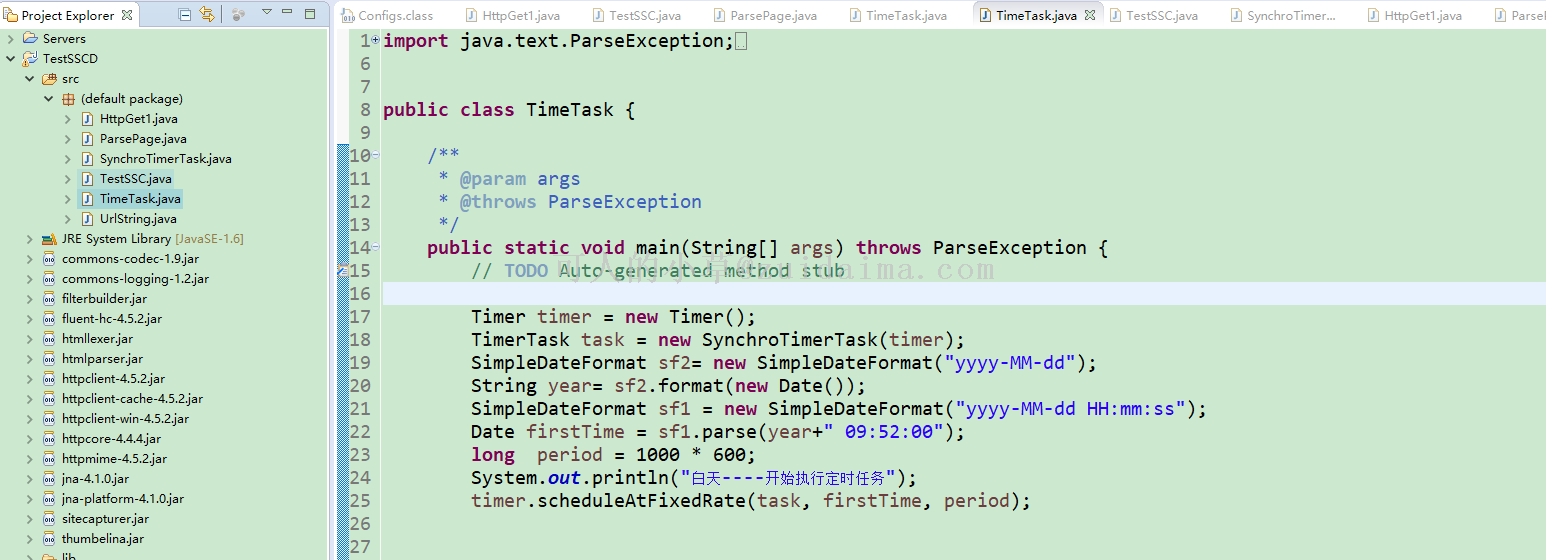
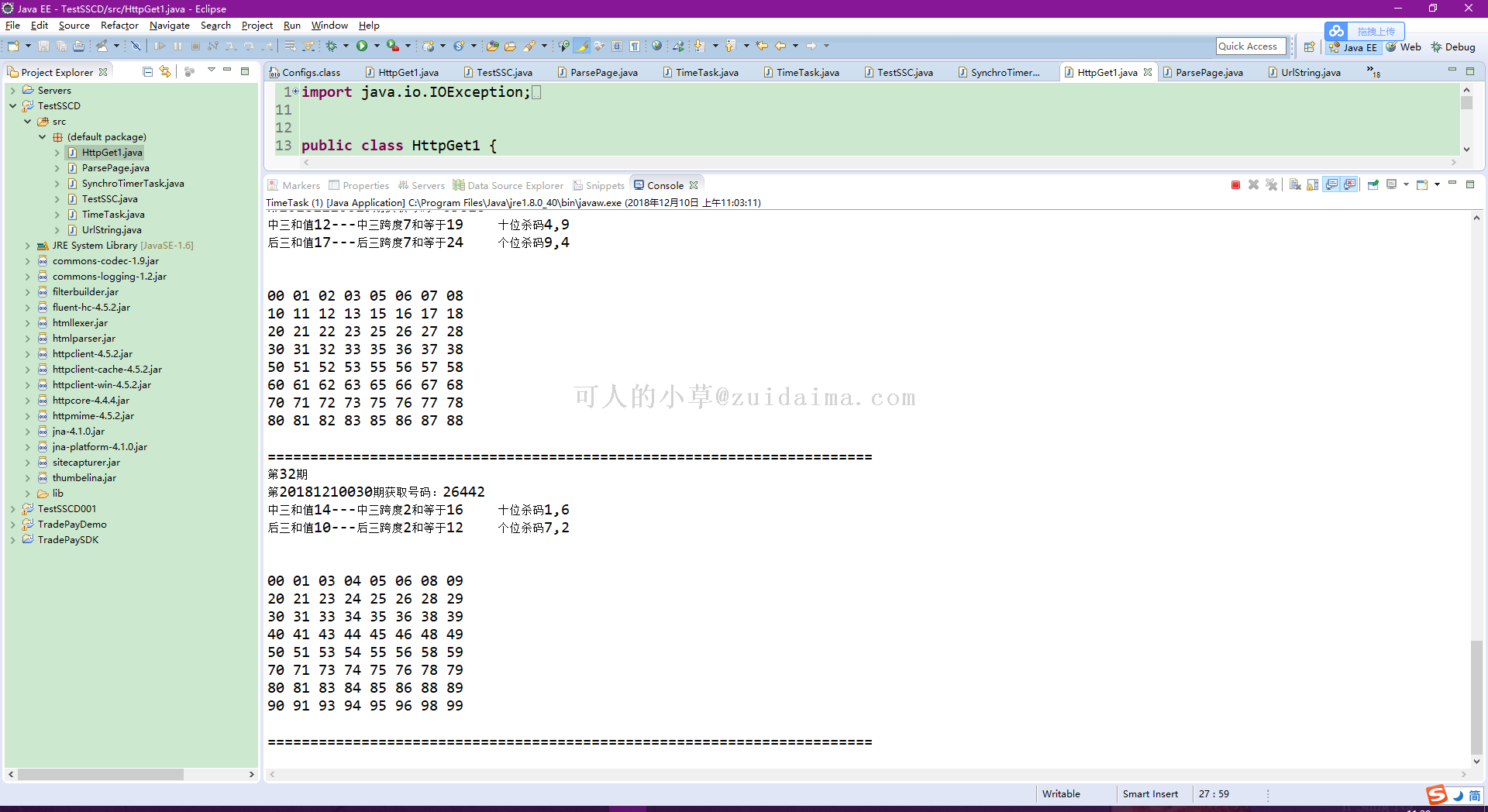
项目描述用httpclient爬取某页面数据,然后通过时时彩杀号规则通过定时任务自动生成需要的计划数据。运行环境jdk6以上版本+eclipse项目技术(必填)httpClient+java数据库文件无jar包文件先关的jar包在项目lib文件里是否原创(转载必填原文地址)原创项目截图(必填)1:运...

lgj123 LV9
2018年11月30日
项目描述python实现猫TV网站小爬虫运行环境python 3.0以上项目技术(必填)python数据库文件无jar包文件无是否原创(转载必填原文地址)转载项目截图(必填)运行截图(必填)注意事项无...


凌秋枫 LV8
2018年11月28日
项目描述这是基于HttpClient+Jsoup实现的简单易用的java工具包,案例以豆瓣网为例爬取书籍信息。如果你想快速的在数据库上获取一定量的数据,这会是个不错的选择!之前在做一个尚车网站项目的时候,那时候要有很多汽车相关信息的素材,就是使用的这种方法,简单方便运行环境IntelliJ IDEA...




fengzf LV16
2018年11月7日
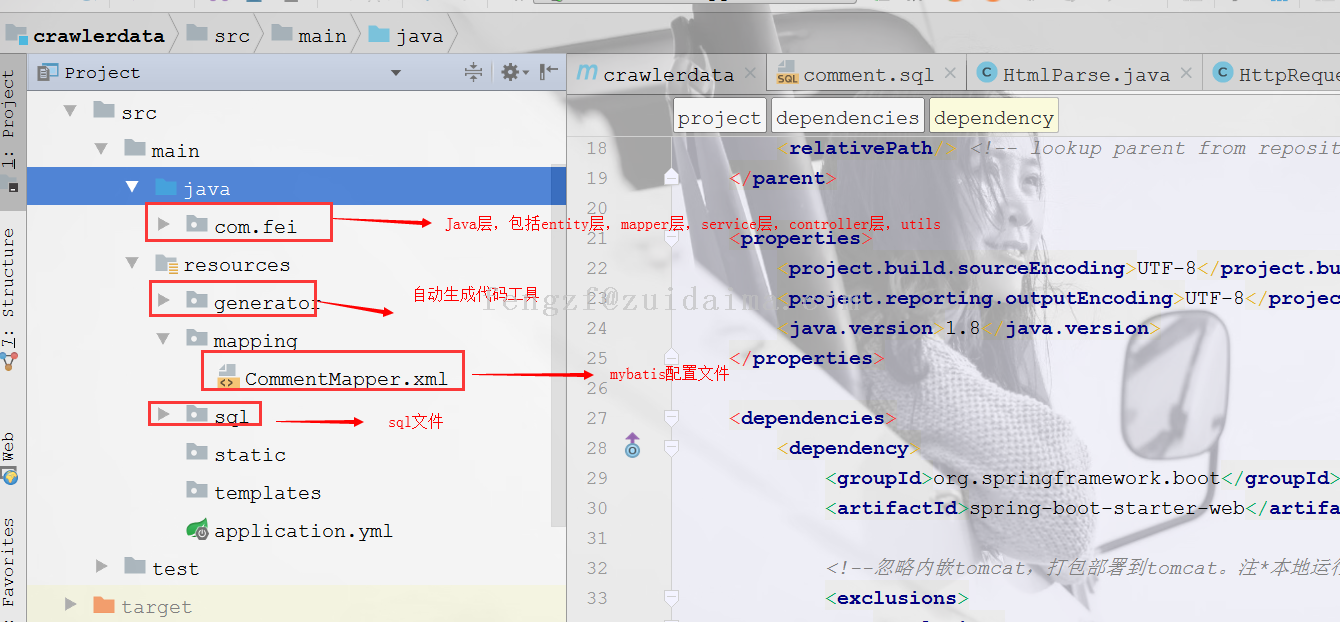
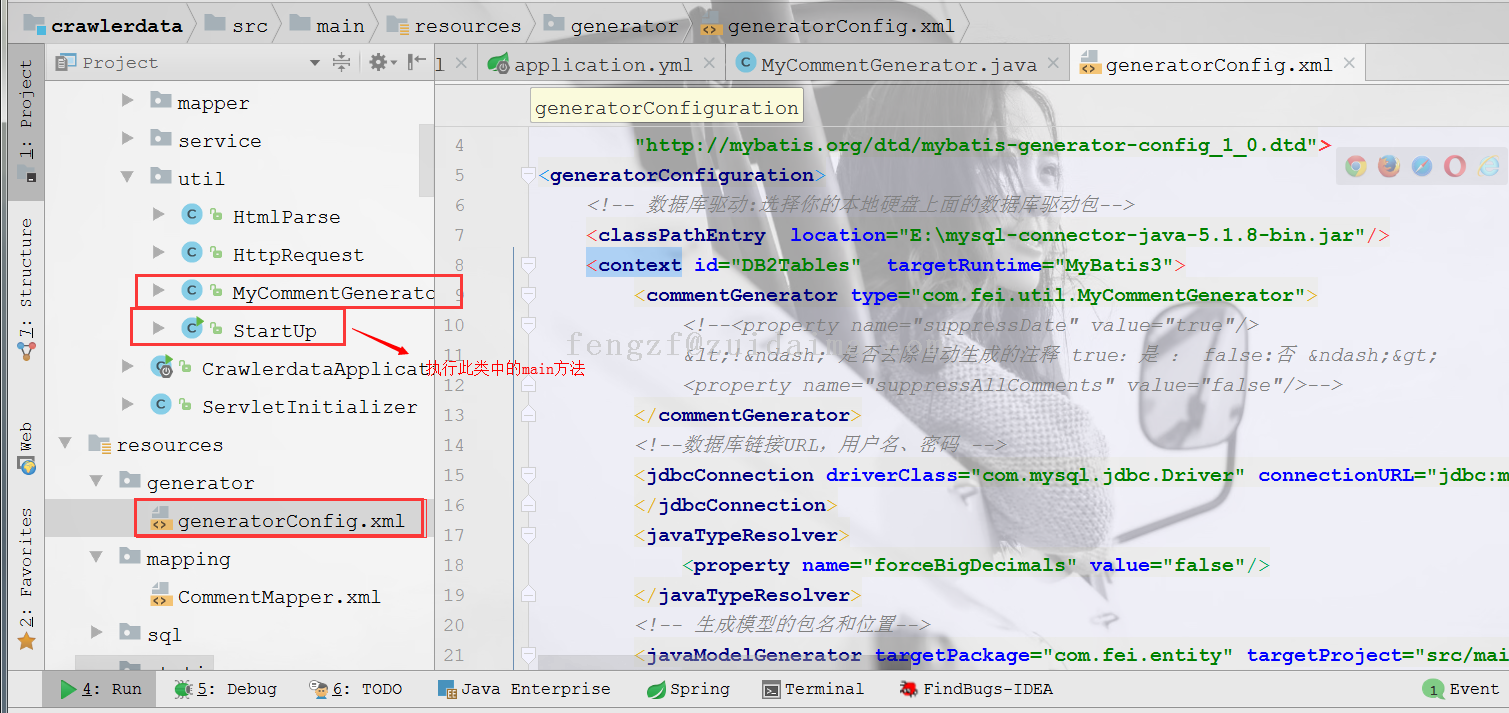
{代码...}项目描述一、需求 获取携程网站用户点评数据保存到数据库中 http://vacations.ctrip.com/grouptravel/p1740331s0...

sys0613 LV12
2018年7月26日
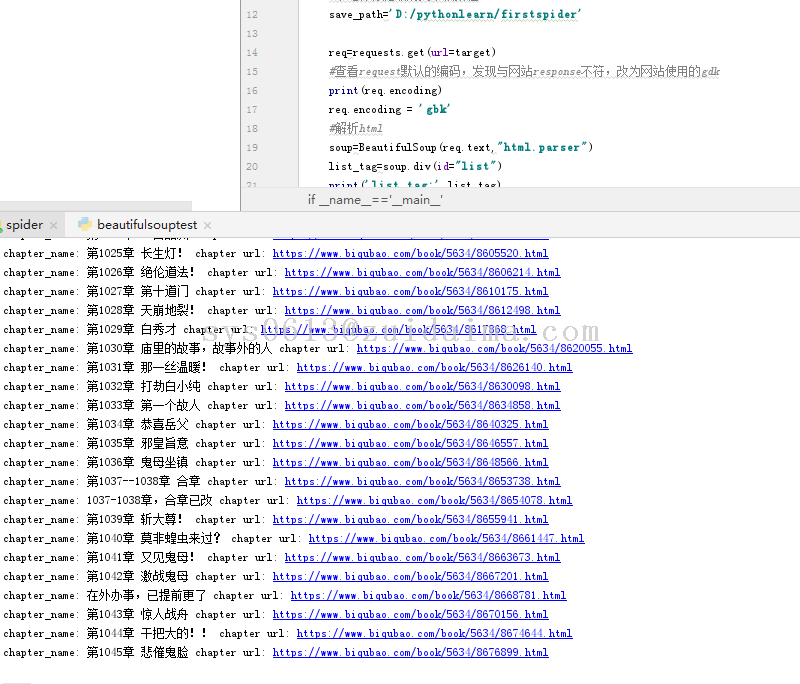
项目描述初学python,练习爬取小说网站,指定小说全部章节运行环境win7+python3.5(安装requests、BeautifulSoup组件)+任意文本编辑工具项目技术(必填)python3+少量html知识数据库文件无jar包文件无是否原创(转载必填原文地址)原创项目截图(必填)仅10几...
自导自演 LV17
2018年7月17日
项目描述花了个把小时的时间简单写了个多线程爬虫,快速爬去第一ppt所有ppt资源运行环境jdk8+lombok插件+maven推荐使用idea打开项目项目技术(必填)jsoup是否原创(转载必填原文地址)原创项目截图(如下)运行截图(如下)...


码农_老王 LV10
2017年12月13日
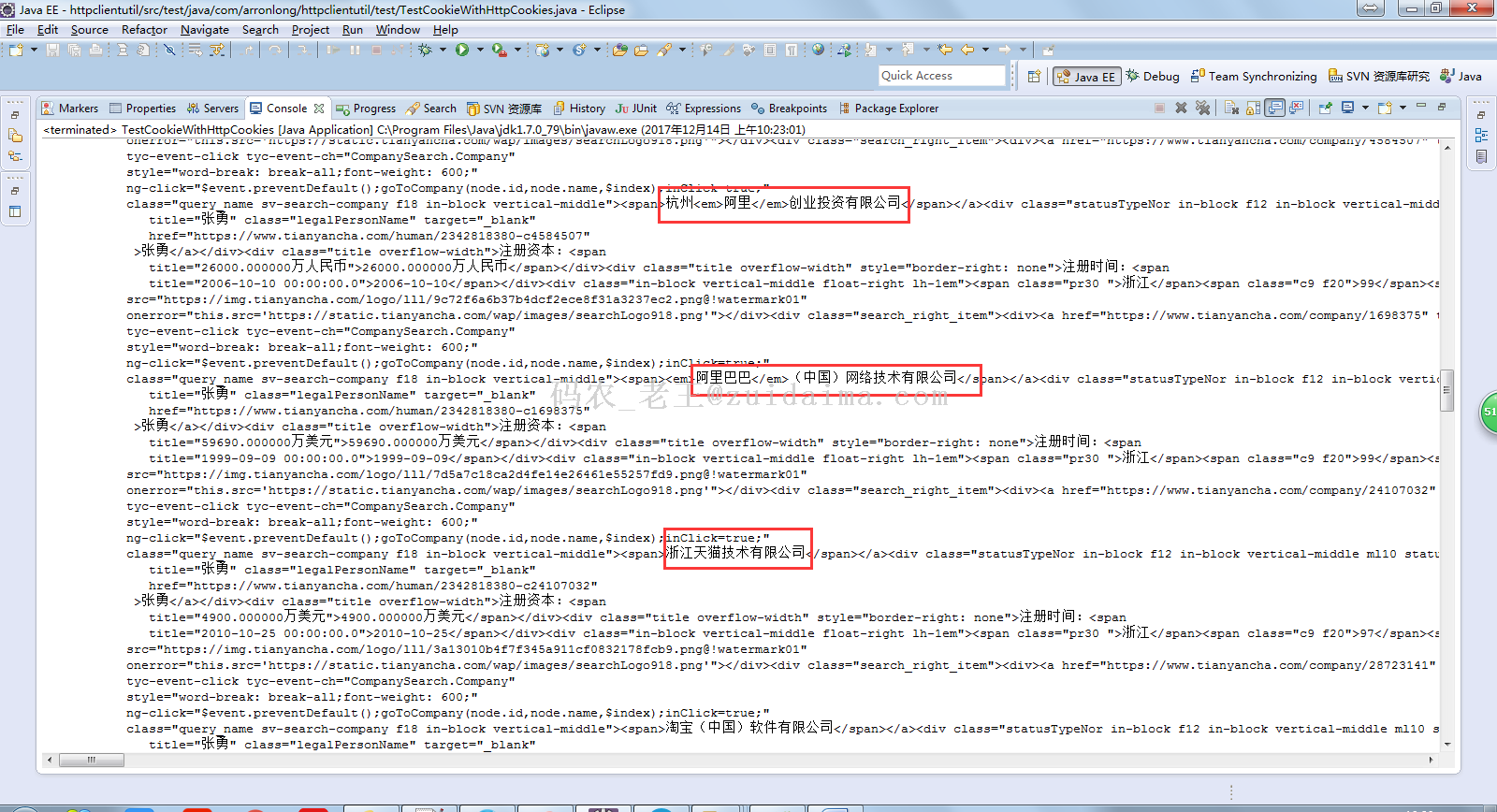
将HTTP简单话,对于喜欢研究爬虫的小伙伴有帮助。可实现文件下载,文件上传,可携带cookie进行请求爬取天眼查页面数据:...

jeety太阳雨 LV14
2017年5月12日
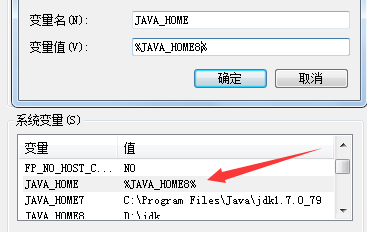
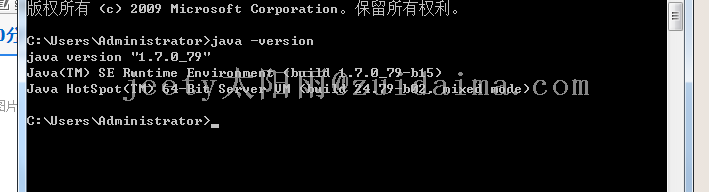
本人技术很差,所以一直对东西很感兴趣,今天看到了网页抓取,参考大神们。然后弄了两个Java文件。一个是bdy jdk1.7,bdy jdk1.8 如果您机器上没有两个jdk的话您可以百度一下怎么弄。很简单。 类似这种 然后更换完成之后,测试一下是否更换完成显示这样子就可以了。 然...