 抓取网站数据代码实例下载
抓取网站数据代码实例下载
随便取个名字_哈哈 LV27
2020年6月14日
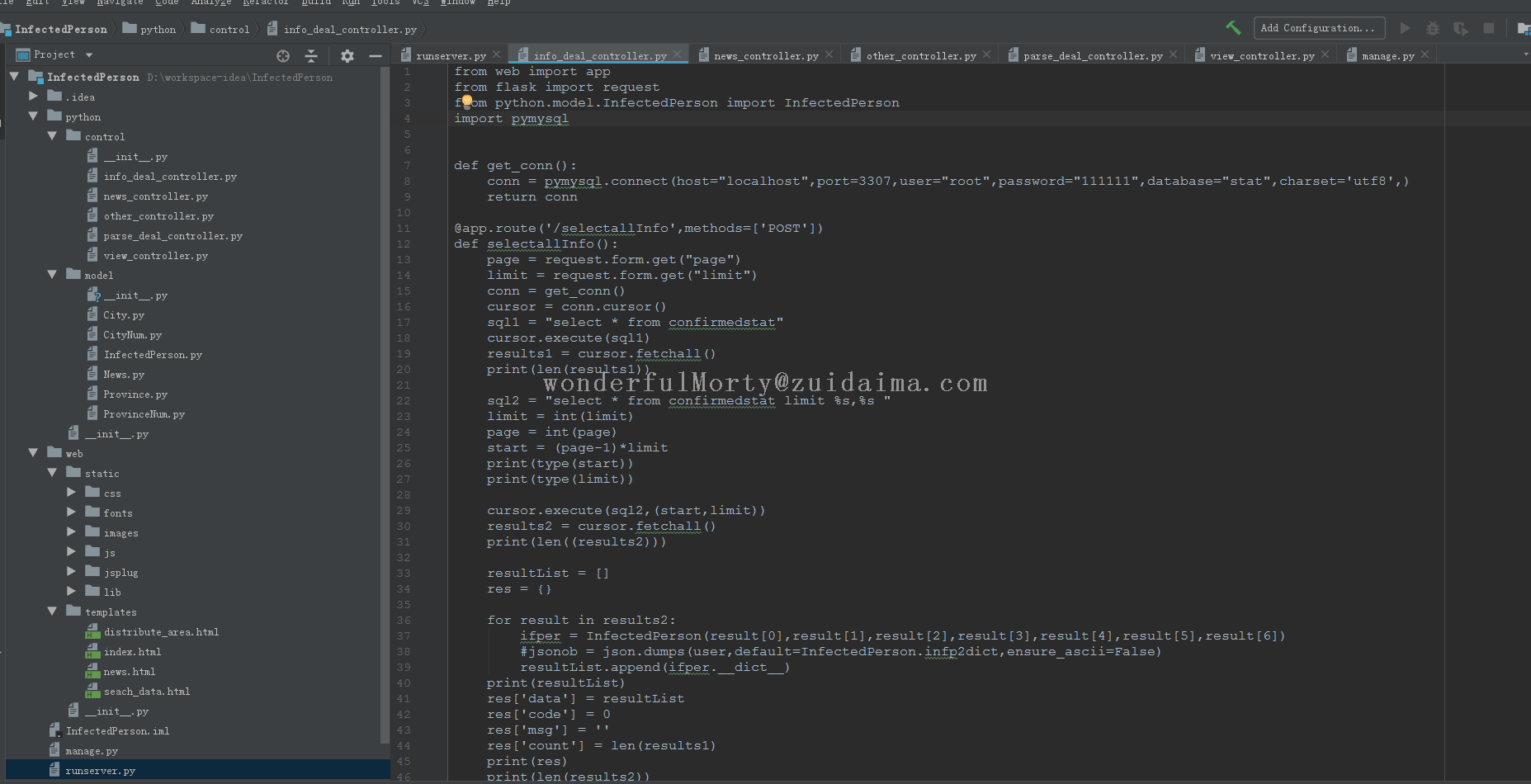
项目描述使用selenium、webdriver爬取淘宝的图片、商品、价格等信息。在命令行界面输入爬取的参数,把参数信息记录到txt文件中,运行爬虫程序后,先使用手机扫码登陆,然后pc端网页会自动翻淘宝的网页,知道翻到淘宝的最后一页,就会停止对商品的爬取web端功能:1.下拉框选择商品搜索2.点击图...


Edson188 LV22
2015年3月4日
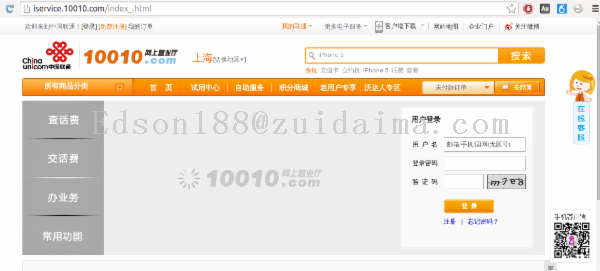
{代码...}1.新建一个maven项目httpclient2.登录中国联通并抓取数据3.使用Get模拟登录,抓取每月账单数据中国联通有两种登录方式:上面两图的区别一个是带验证码,一个是不带验证码, 下面将先解决不带验证码的登录.这里有两个难点,一是验证码,二uvc码;验证码,这里将其写到本地,然后人工输入,这个...



serical LV12
2015年5月19日
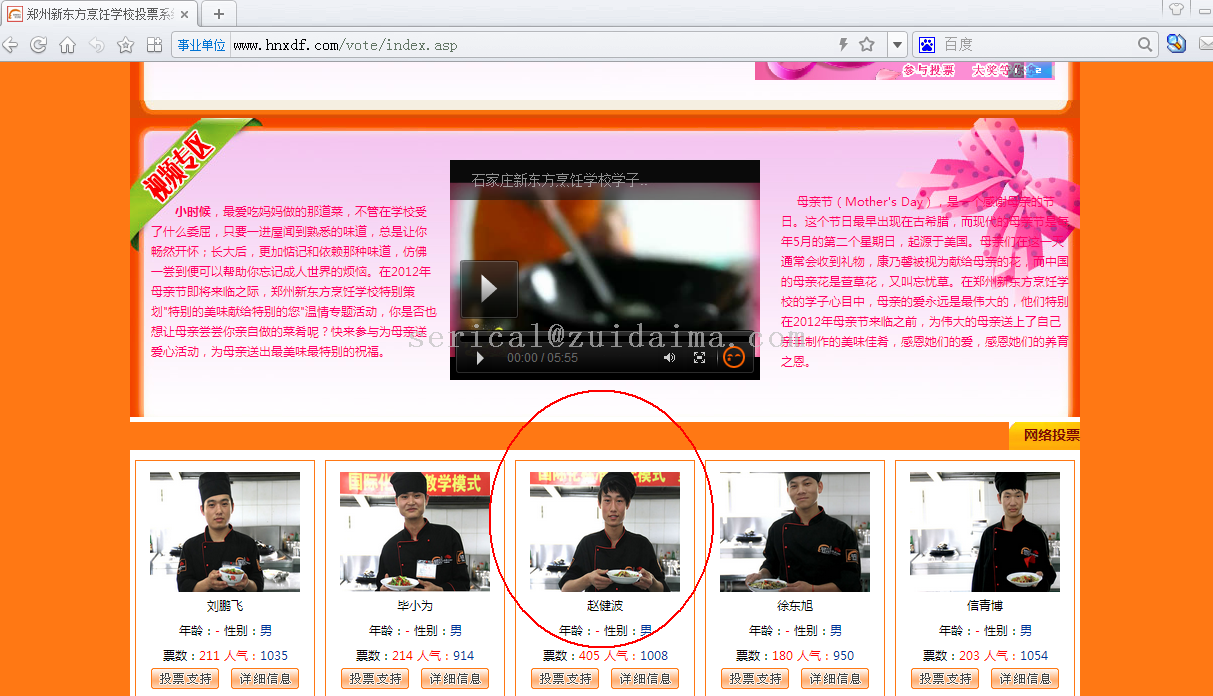
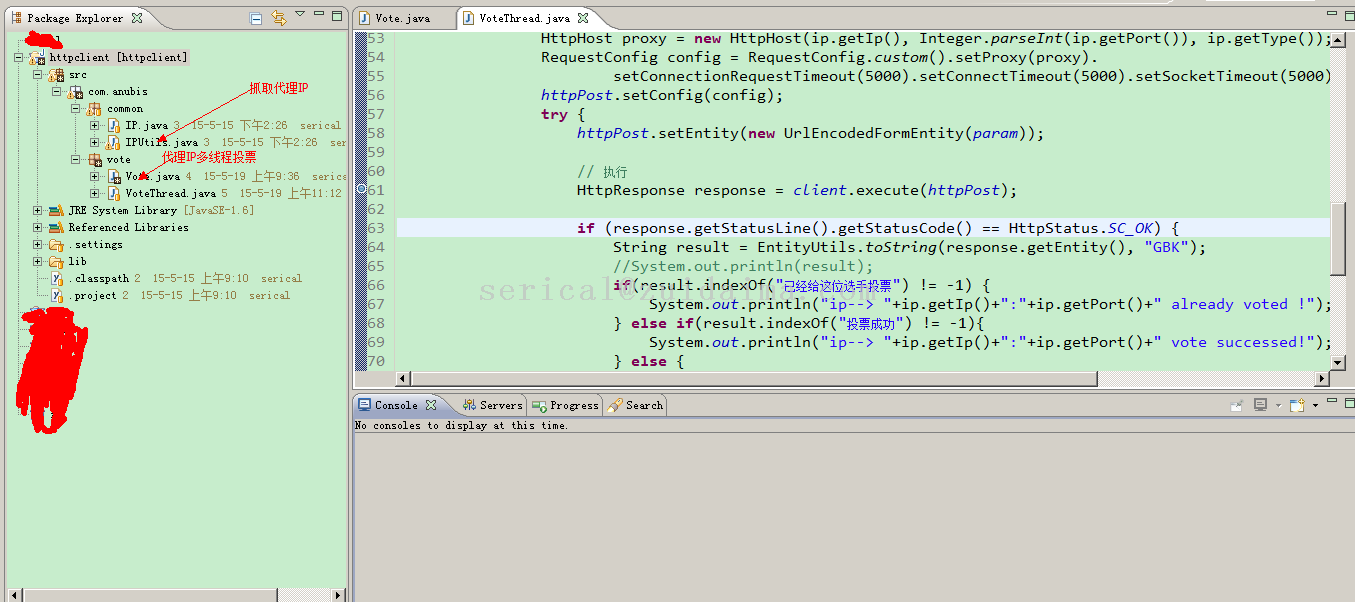
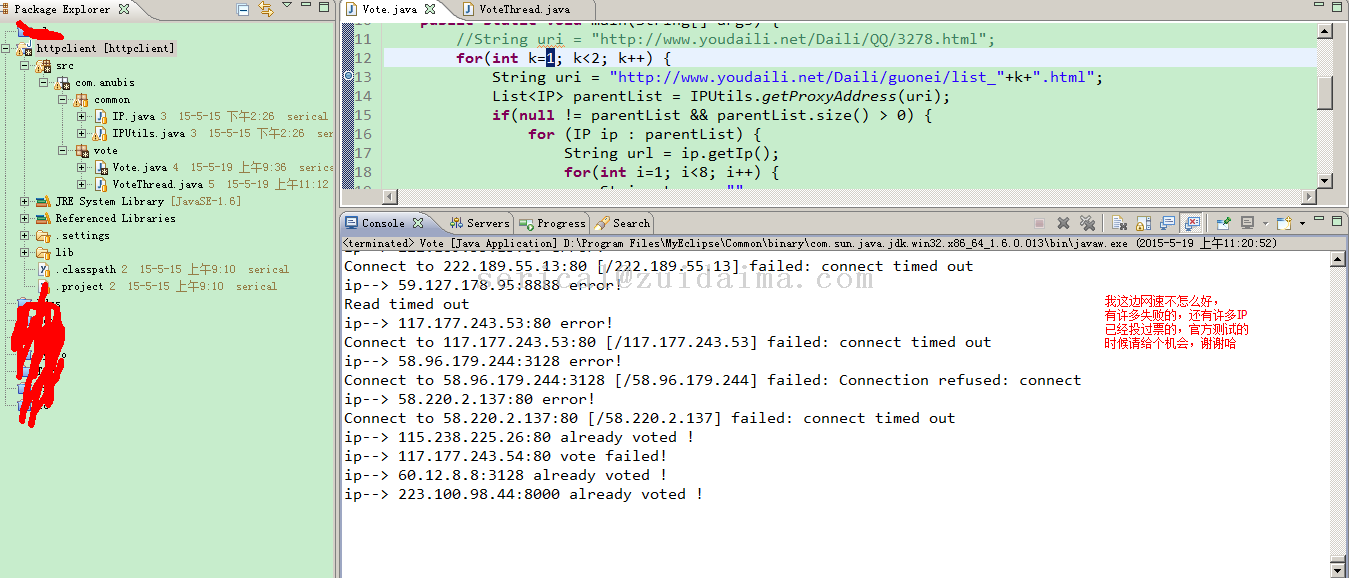
前几天有个朋友给我发了个链接说是让我去投票,我去看了下,选择了目标投票,再点的时候给我说一个IP只能投一次,作为一只猿当然得想法去突破它,就想着用HttpClient去代理提交请求实现刷票,由于朋友的活动已经关闭了,这里找了另一个网站做测试,http://www.hnxdf.com/vote/ind...
cuihui123 LV6
2020年7月4日
项目描述基础环境:python + flask + vue + element-ui + echartspython_spiders -- 爬虫后台项目python_spiders_web -- 爬虫前台项目运行环境python 3.8.3 + nginx + mysql项目技术(必填)Python...

Garfields LV9
2015年11月18日
不用开发,直接使用。支持伪造头,伪造Cookie等可以导出文件可以使用div 页面元素就能爬取内容导入Eclipse直接用[+]com.pga.* [-]crawler.* //爬虫处...

丶附耳聆听 LV21
2016年10月10日
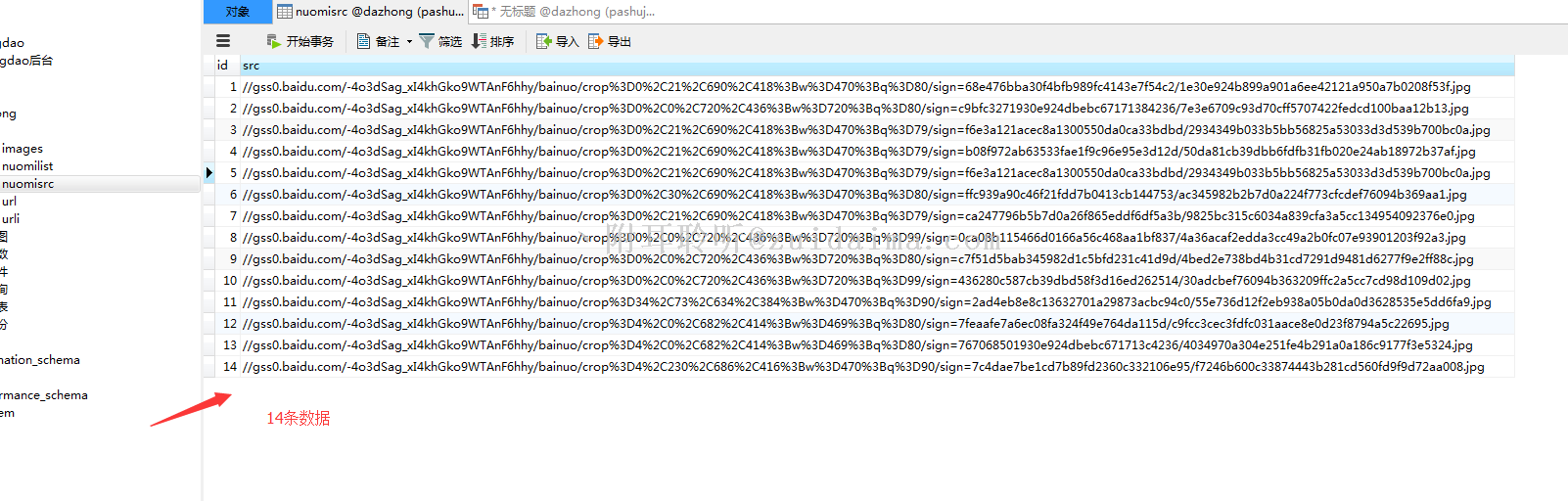
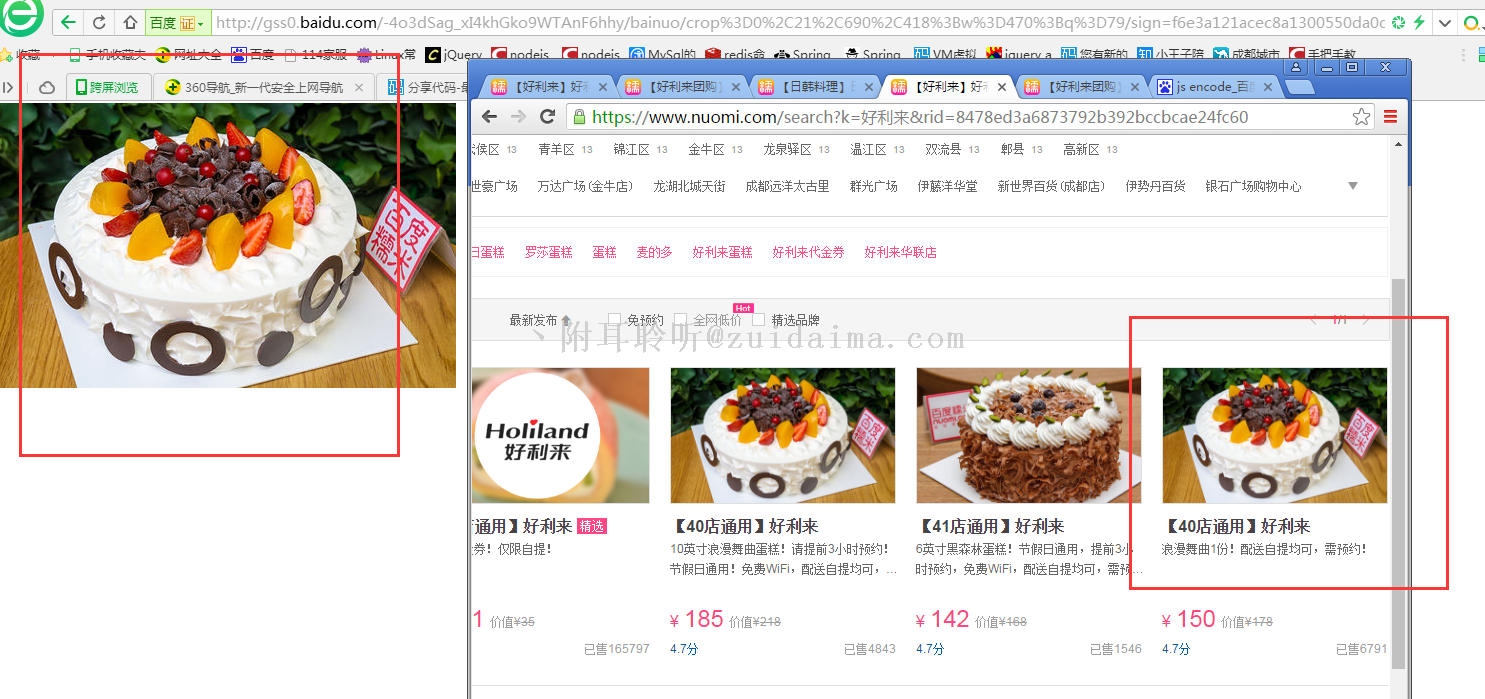
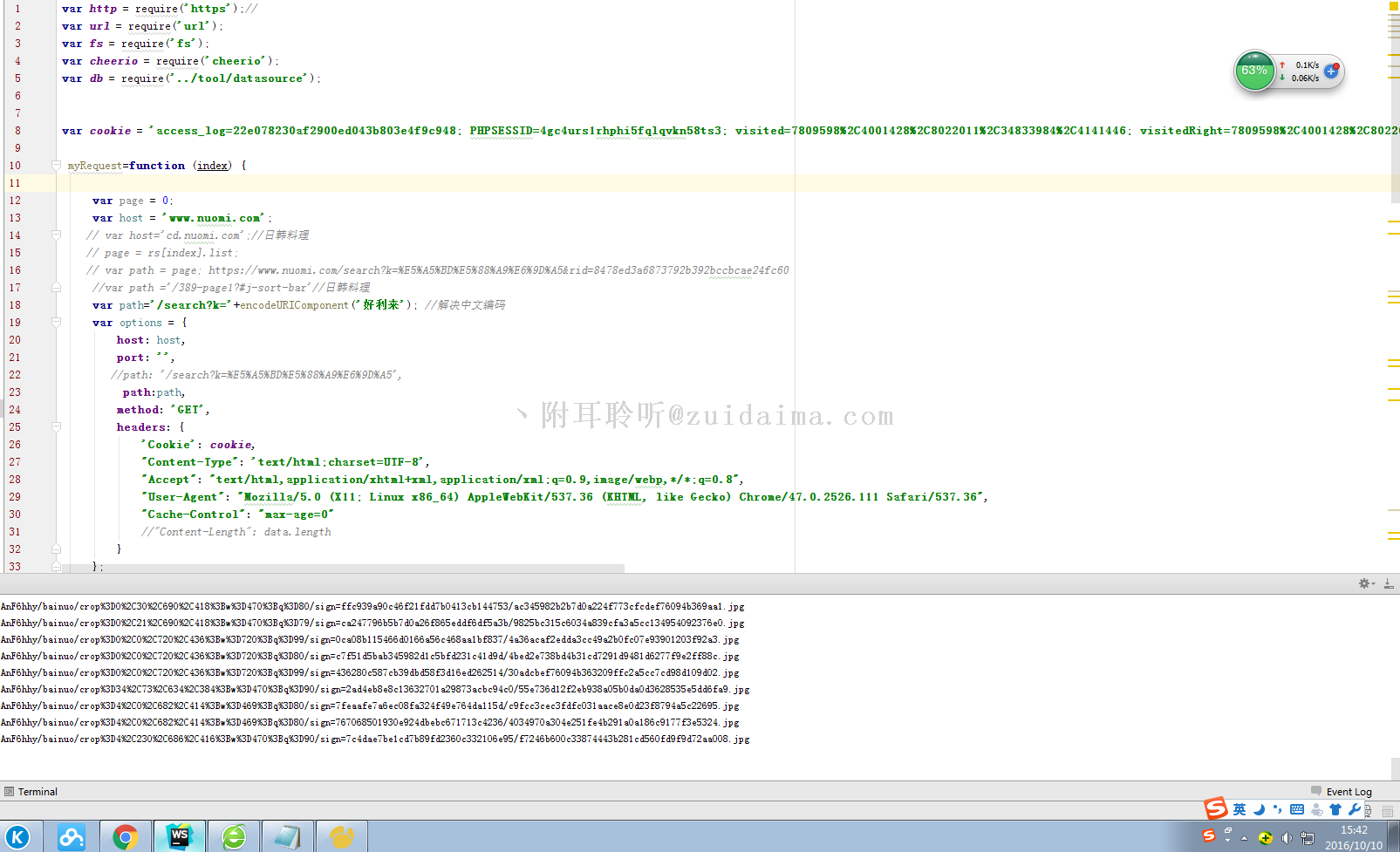
nodejs爬百度糯米图片,拿去就能用。这里演示第五条数据...

骑着猪猪去逛街 LV32
2013年11月25日
{代码...}如果要使用注解方式实现,也是支持的。由最代码官方编辑于2013-12-31 22:08:41...


fengzf LV16
2018年11月7日
{代码...}项目描述一、需求 获取携程网站用户点评数据保存到数据库中 http://vacations.ctrip.com/grouptravel/p1740331s0...

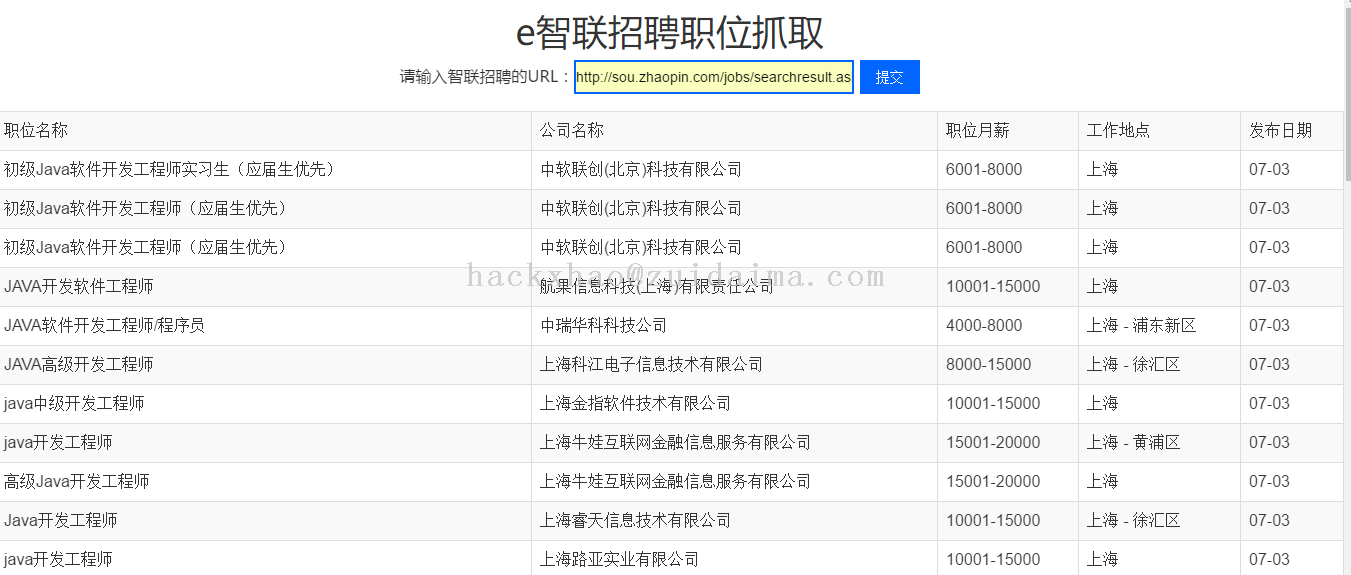
hackxhao LV15
2016年7月3日
{代码...}
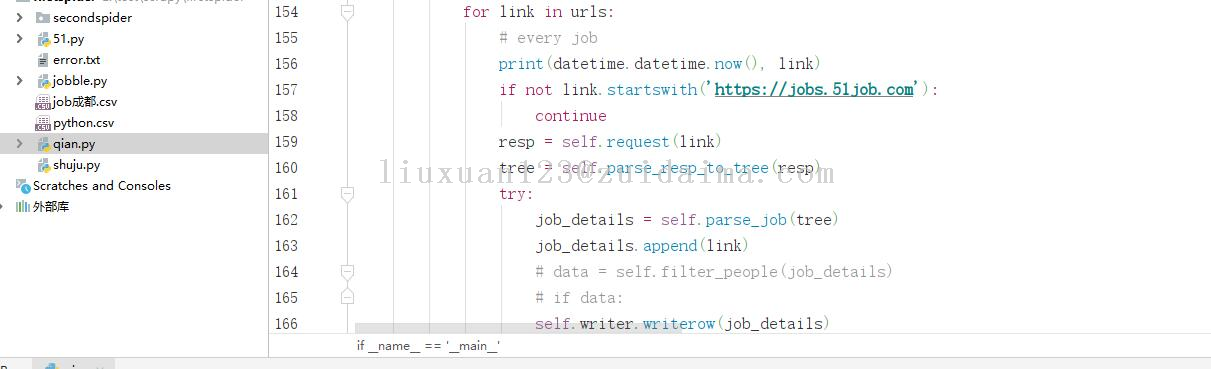
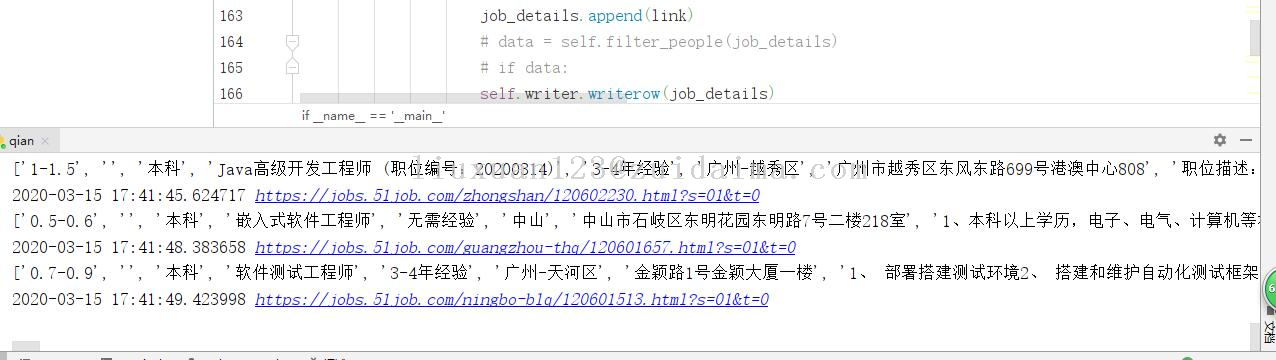
liuxuan123 LV1
2020年3月15日
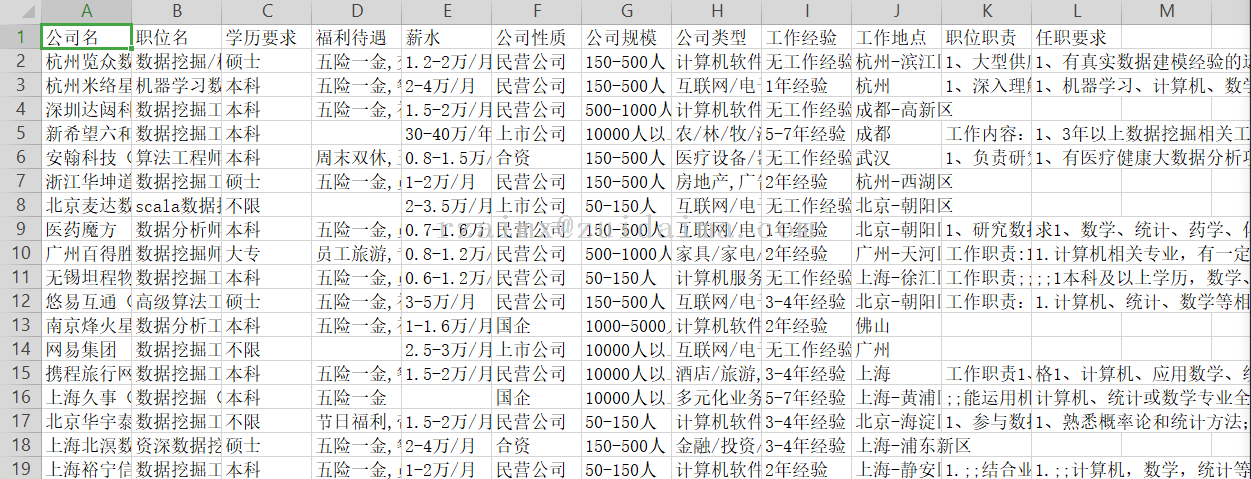
项目描述本项目数据来源于前程无忧,利用爬虫技术爬取前程无忧招聘信息,爬取的信息包括公司名称、职位名称、职位、薪水、工作经验、学历要求、工作地点、公司领域、公司规模;总共爬取了3000多条记录;运行环境python3.8+pycharm项目技术(必填)python爬虫依赖包文件(可选)需要安装如下框架...


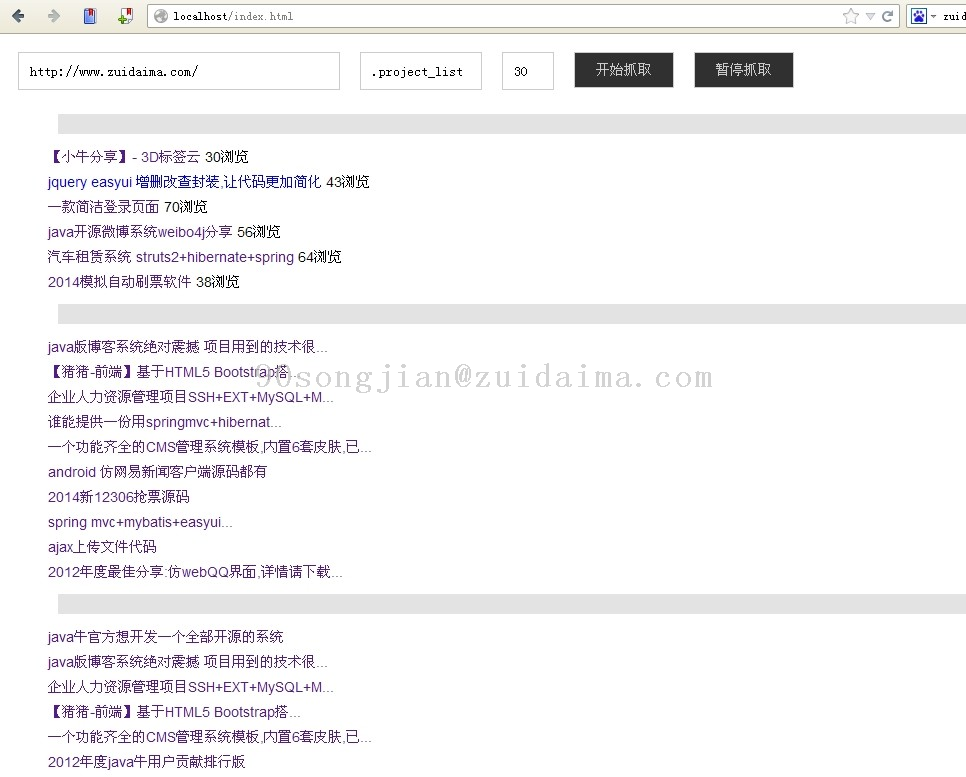
90songjian LV8
2013年7月30日
一个使用jsoup爬取内容的实例获取zuidaima首页的分享列表:项目截图由最代码官方编辑于2014-1-18 22:46:50...
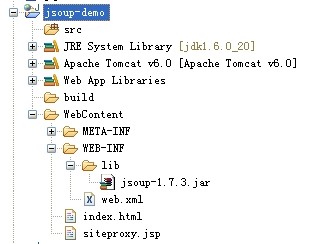

jeety太阳雨 LV14
2017年5月12日
本人技术很差,所以一直对东西很感兴趣,今天看到了网页抓取,参考大神们。然后弄了两个Java文件。一个是bdy jdk1.7,bdy jdk1.8 如果您机器上没有两个jdk的话您可以百度一下怎么弄。很简单。 类似这种 然后更换完成之后,测试一下是否更换完成显示这样子就可以了。 然...
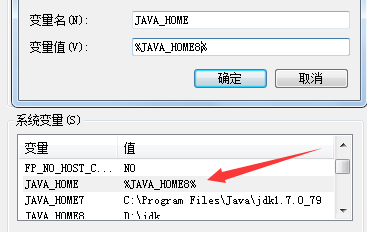
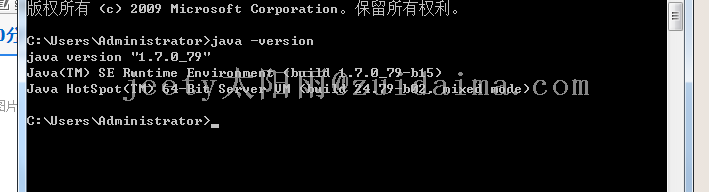

socket LV6
2021年1月11日
项目描述python爬取包括首页、搜索、分类、详情、章节目录、章节内容运行环境Python3.6+项目技术(必填)python第三方库requests,urllib,lxml依赖包文件pip install requestspip install urllib3pip install lxml是否原...

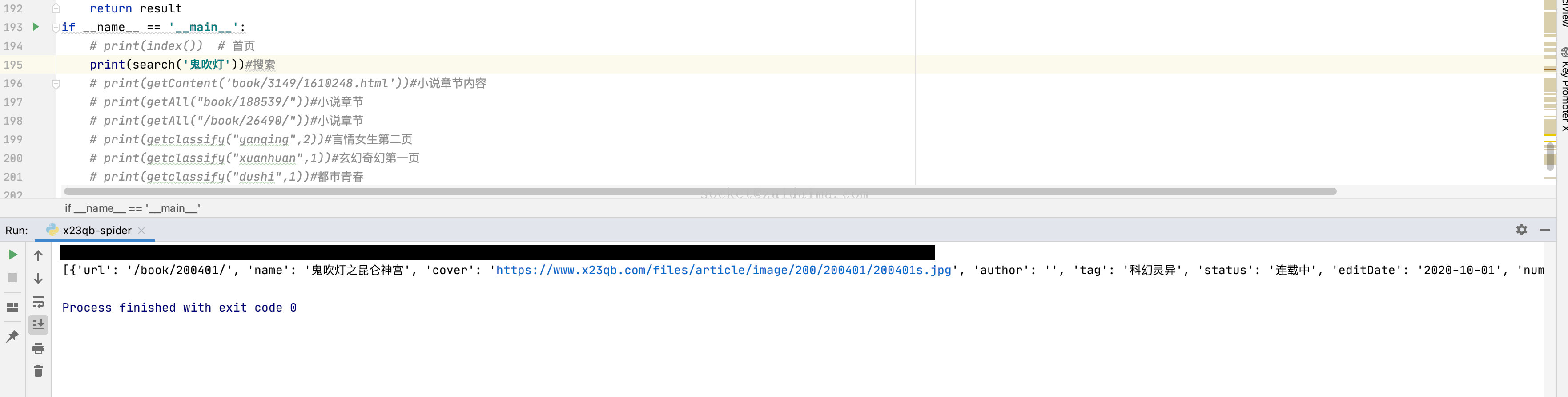

rzaimx LV3
2019年3月2日
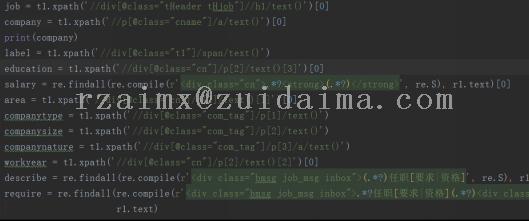
{代码...}项目描述从前程无忧招聘网站上进行网页抓取,提取各项数据,数据包含多个维度,分别是城市、岗位名称、公司名字、公司规模、公司类型、经验要求、学历要求、专业要求、福利待遇和所属行业等。对爬取的数据进行数据清洗及标准化后,实现数据分析和可视化。最后实践apriori算法,进行频繁项集提取及关联分析。运行环境...

自导自演 LV17
2018年7月17日
项目描述花了个把小时的时间简单写了个多线程爬虫,快速爬去第一ppt所有ppt资源运行环境jdk8+lombok插件+maven推荐使用idea打开项目项目技术(必填)jsoup是否原创(转载必填原文地址)原创项目截图(如下)运行截图(如下)...


请叫我小C LV19
2019年2月12日
项目描述想不想免费下载一首某Q的付费音乐?代码中紧演示了mp3的下载,其余格式均已实现,需要自己调整代码,教你用代码免费下载,紧供学习,请勿用于商业。运行环境jdk7+eclipse+maven项目技术(必填)java数据库文件无项目截图(必填)运行截图(必填)...



凌秋枫 LV8
2018年11月28日
项目描述这是基于HttpClient+Jsoup实现的简单易用的java工具包,案例以豆瓣网为例爬取书籍信息。如果你想快速的在数据库上获取一定量的数据,这会是个不错的选择!之前在做一个尚车网站项目的时候,那时候要有很多汽车相关信息的素材,就是使用的这种方法,简单方便运行环境IntelliJ IDEA...



可人的小草 LV3
2018年12月10日
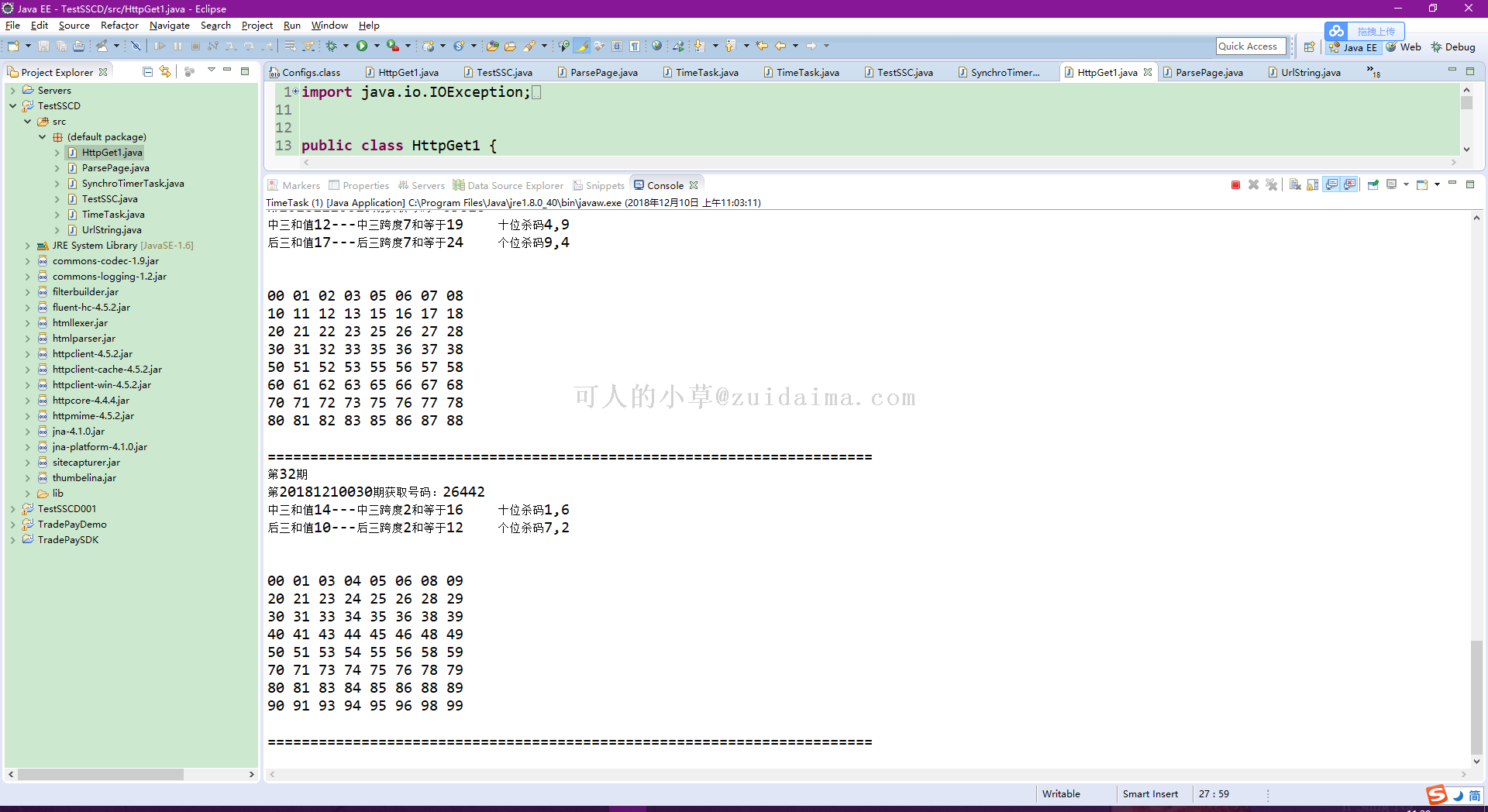
项目描述用httpclient爬取某页面数据,然后通过时时彩杀号规则通过定时任务自动生成需要的计划数据。运行环境jdk6以上版本+eclipse项目技术(必填)httpClient+java数据库文件无jar包文件先关的jar包在项目lib文件里是否原创(转载必填原文地址)原创项目截图(必填)1:运...

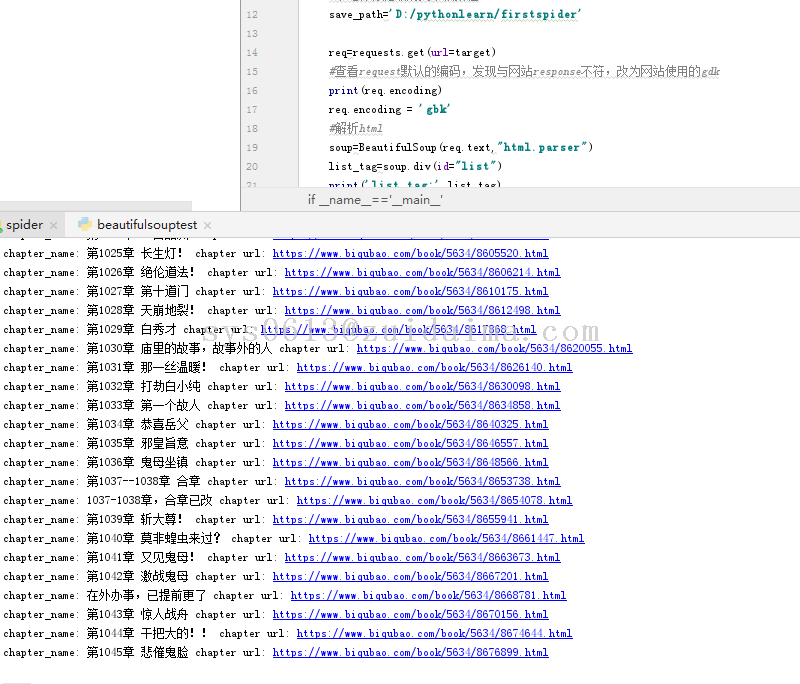
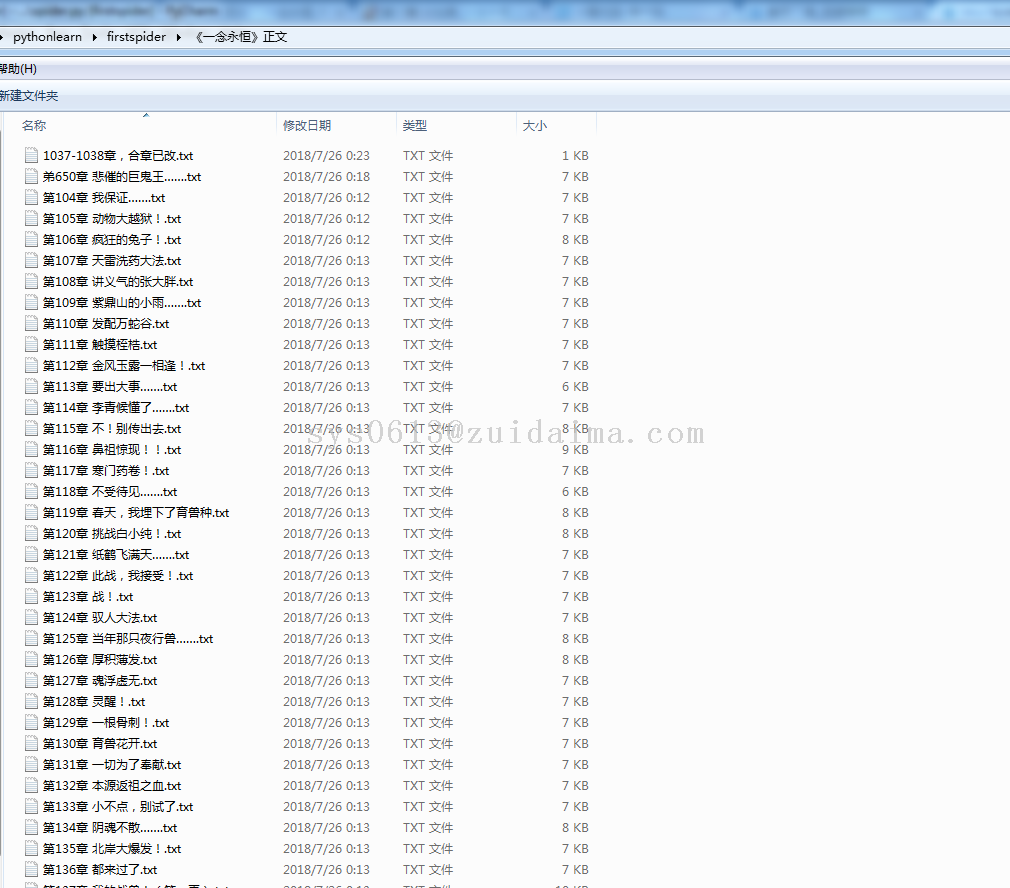
sys0613 LV12
2018年7月26日
项目描述初学python,练习爬取小说网站,指定小说全部章节运行环境win7+python3.5(安装requests、BeautifulSoup组件)+任意文本编辑工具项目技术(必填)python3+少量html知识数据库文件无jar包文件无是否原创(转载必填原文地址)原创项目截图(必填)仅10几...