已注销用户
2015-09-17 15:38:38
原
Java语言和Python语言编写相同功能脚本请求网页刷某个网站的博客阅读量
这两天发现一个新网站,无聊就去注册了一个账号。为了混个脸熟,写了一篇博客,写完后,习惯性的去浏览看看。然后发现一个小小的bug,阅读量变了,于是想到了最代码貌似没有这回事。最代码里面没有登录的时候去浏览文章或博客或分享的时候浏览量都不没有增加。所以无聊就写写代码,刷刷浏览量
思路:用循环获取网页内容打印出来(一定要打印网页内容不然浏览量不会增加的)
public static String doHttp(HttpMethod result,int timeout, String charset){
HttpClient client = new HttpClient();
try {
HttpConnectionManagerParams managerParams = client
.getHttpConnectionManager().getParams();
managerParams.setConnectionTimeout(timeout);
client.executeMethod(result);
InputStream resStream = result.getResponseBodyAsStream();
BufferedReader br = new BufferedReader(new InputStreamReader(resStream, charset));
StringBuffer resBuffer = new StringBuffer();
String resTemp = "";
while ((resTemp = br.readLine()) != null) {
resBuffer.append(resTemp);
}
return resBuffer.toString();
}
catch (HttpException e)
{
return null;
}
catch (IOException e) {
return null;
}
catch (Exception e) {
return null;
} finally {
result.releaseConnection();
}
}
这里要一个HttpClient 的jar包,依赖HttpClient写一个获取网页内容的方法
/**
* 通过get方式取得html
* @param url
* @param timeout
* @param charset
* @return
*/
public static String getHTMLByUrl(String url, int timeout, String charset){
if (charset == null)
charset = "utf-8";
HttpMethod result = new GetMethod(url);
return doHttp(result,timeout,charset);
}
接下来 写个main方法看demo:
public static void main(String[] args) {
for(int i =0;i<1000;i++){
String url ="http://www.XXX.com/user/10686/blog/400";
String html = getHTMLByUrl(url, 10000, null);
System.out.println(html);
System.err.println(i);
}
}
URL里面的 我就不公布了
看运行图:
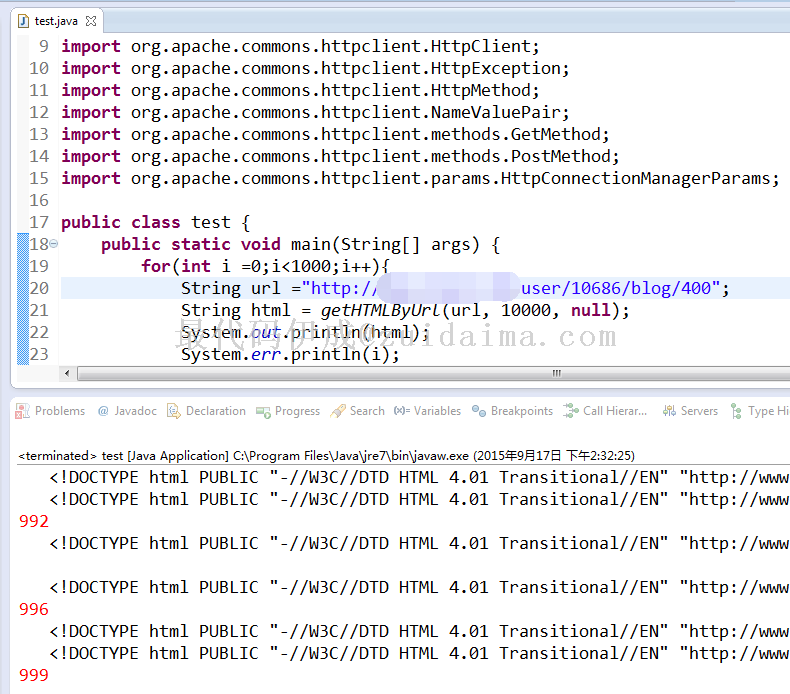
接下来看看 python版的吧:
思路是一样的,根据URL循环打印出网页内容既可以了。上代码:
import urllib2;
i =0
while i<1000:
response = urllib2.urlopen('http://www.XXX.com/user/10686/blog/400')
html = response.read()
i=i+1
print(html)
print(i)
运行图:
 发现了没有,python代码很少,简洁明了。
发现了没有,python代码很少,简洁明了。
最后上张博客刷了后的博客阅读量的图:
 哈哈 Java刷了1000次 python刷了1000次
哈哈 Java刷了1000次 python刷了1000次
然而这并没有什么乱用 ( HEY GUY , JUST HAVA FUN )
猜你喜欢
 相关代码
最近下载
相关代码
最近下载
 最近浏览
最近浏览



