 搜索"java网络爬虫蜘蛛源码"的代码列表
搜索"java网络爬虫蜘蛛源码"的代码列表
hegang3 LV6
2018年12月18日
项目描述运用python语言编写,使用scrapy框架。专业数据爬取框架Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。运行环境pycharm python 项目技术(必填)python&nbs...

kenjoyIT LV9
2015年6月28日
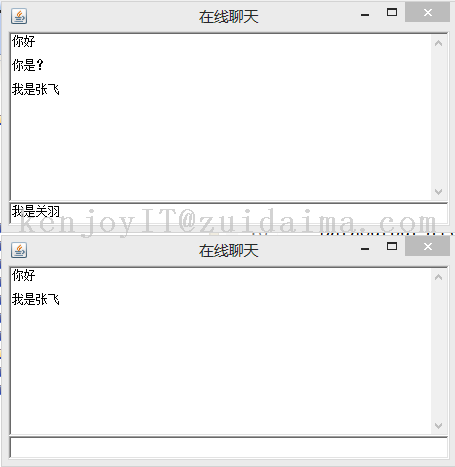
自己用java swing实现简易的聊天室,用于学习线程与网络编程的基础知识...
可人的小草 LV3
2018年12月10日
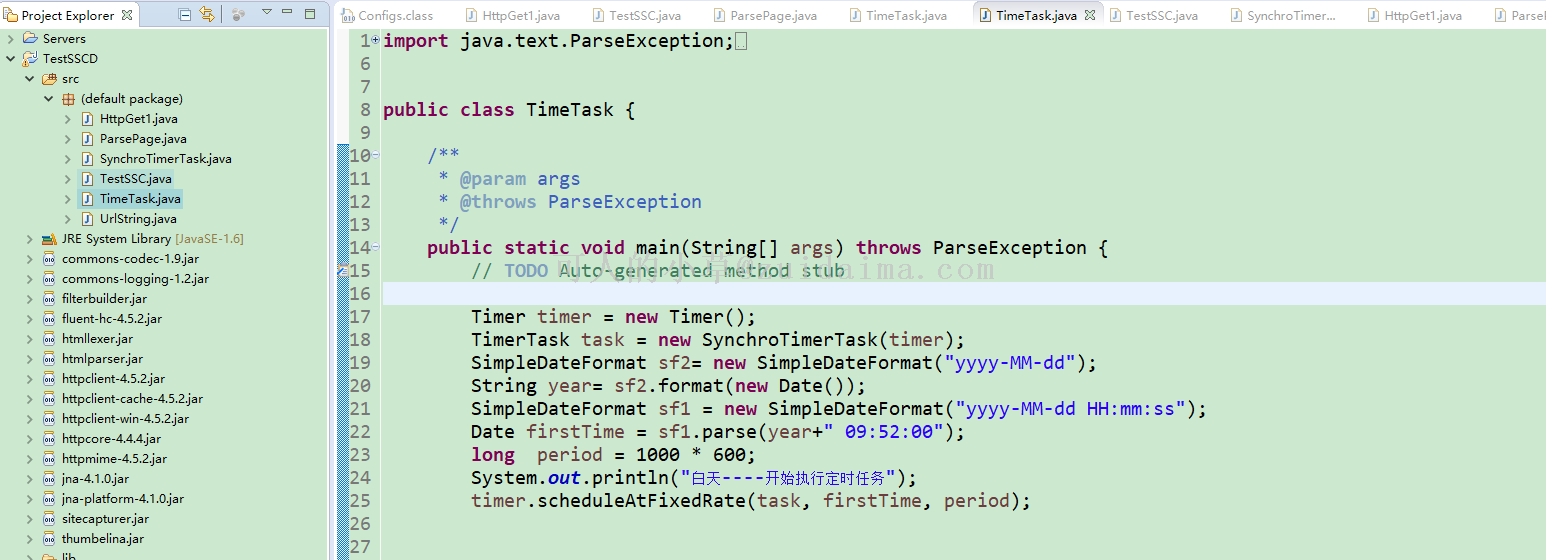
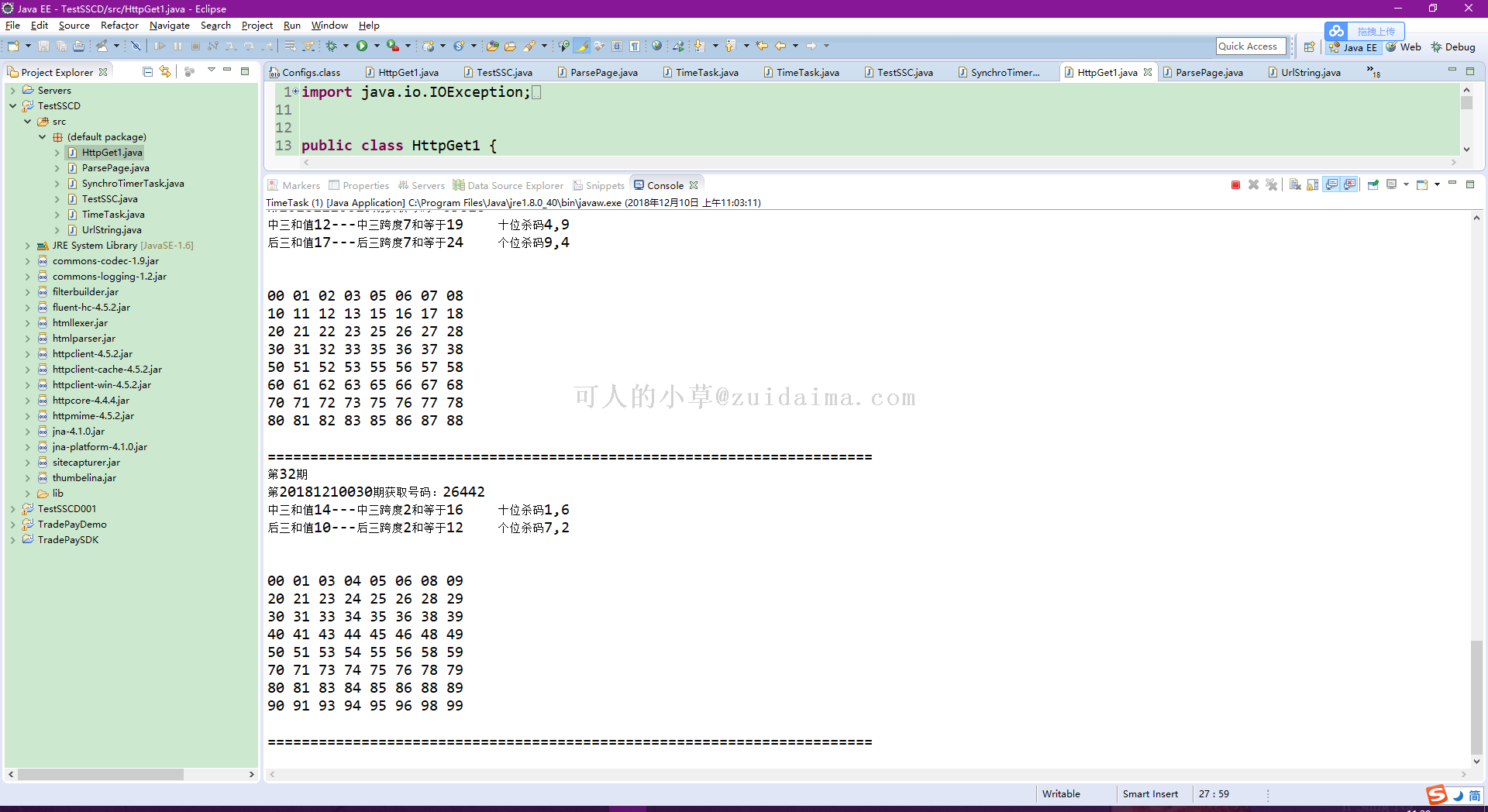
项目描述用httpclient爬取某页面数据,然后通过时时彩杀号规则通过定时任务自动生成需要的计划数据。运行环境jdk6以上版本+eclipse项目技术(必填)httpClient+java数据库文件无jar包文件先关的jar包在项目lib文件里是否原创(转载必填原文地址)原创项目截图(必填)1:运...

dafeigenihao LV13
2017年4月16日
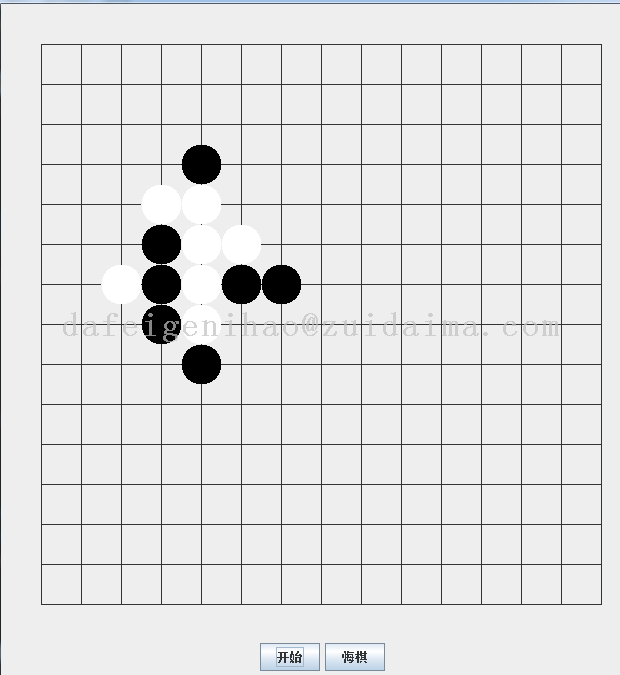
java基础版五子棋适合新手实现了简单的ai算法\...


玫瑰感觉 LV23
2015年6月3日



凌秋枫 LV8
2018年11月28日
项目描述这是基于HttpClient+Jsoup实现的简单易用的java工具包,案例以豆瓣网为例爬取书籍信息。如果你想快速的在数据库上获取一定量的数据,这会是个不错的选择!之前在做一个尚车网站项目的时候,那时候要有很多汽车相关信息的素材,就是使用的这种方法,简单方便运行环境IntelliJ IDEA...




最代码官方 LV167
2013年8月10日
{代码...}抓包工具fidder是一个很轻巧的可以获取浏览器,程序的http,https请求的软件。百科地址:http://baike.baidu.com/view/868685.htm官网地址:http://fiddler2.com/firefox的fidder插件而java程序需要设置proxy才能生效:&...


轻叹 LV3
2013年8月7日
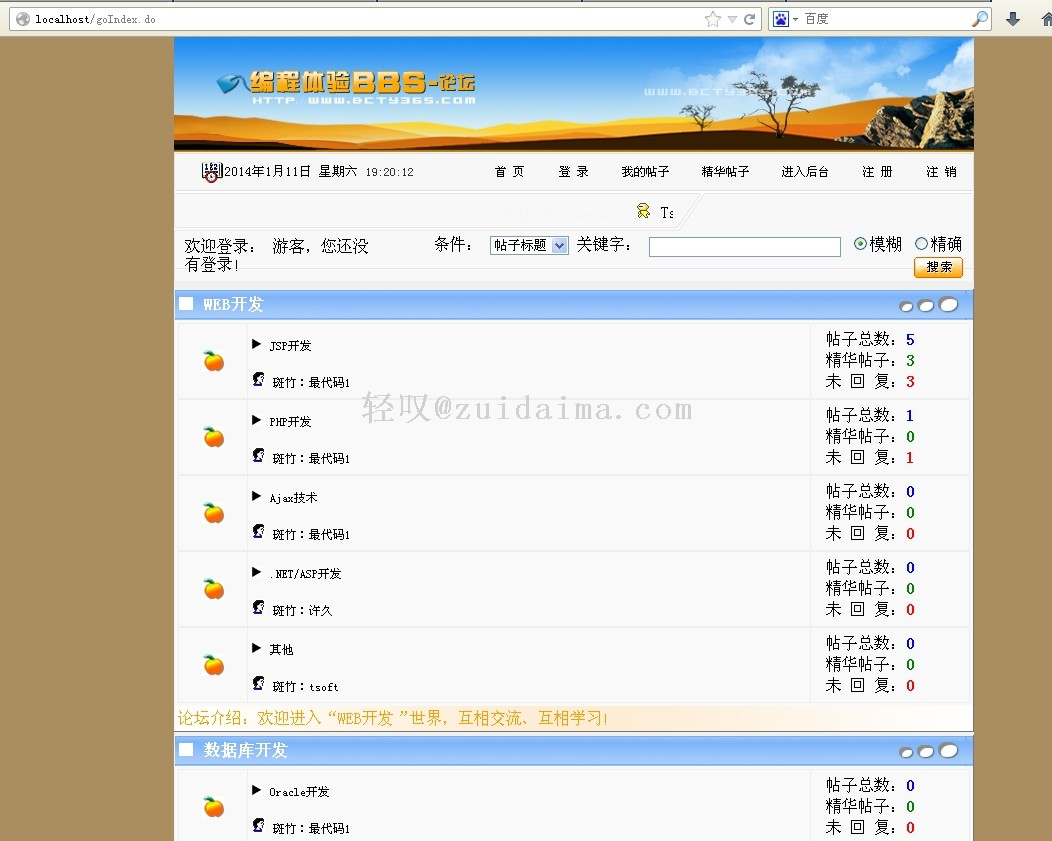
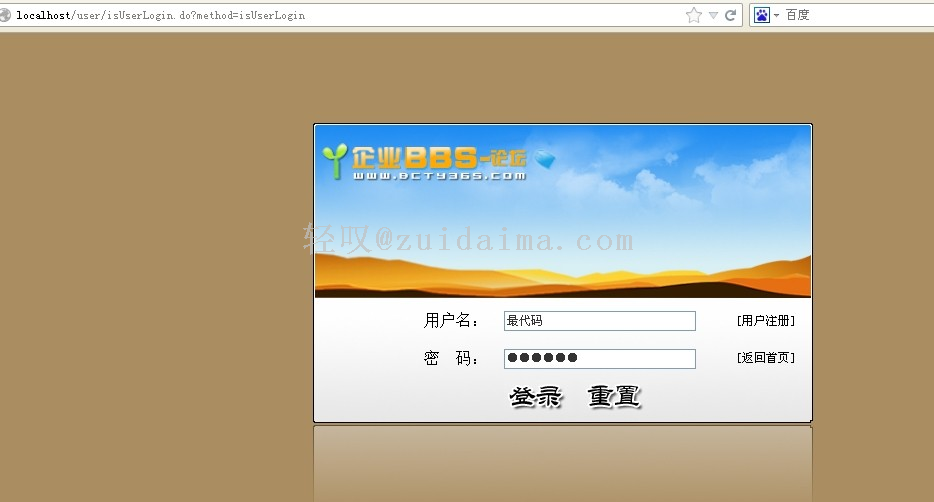
Jsp论坛系统(BBS)源码首页http://localhost:端口/项目/goIndex.do登陆页面http://localhost:端口/项目/user/isUserLogin.do?method=isUserLogin项目截图由最代码官方编辑于2015-4-13 16:40:43...

crazy11crazy LV30
2013年12月21日

syc1013 LV5
2015年3月14日
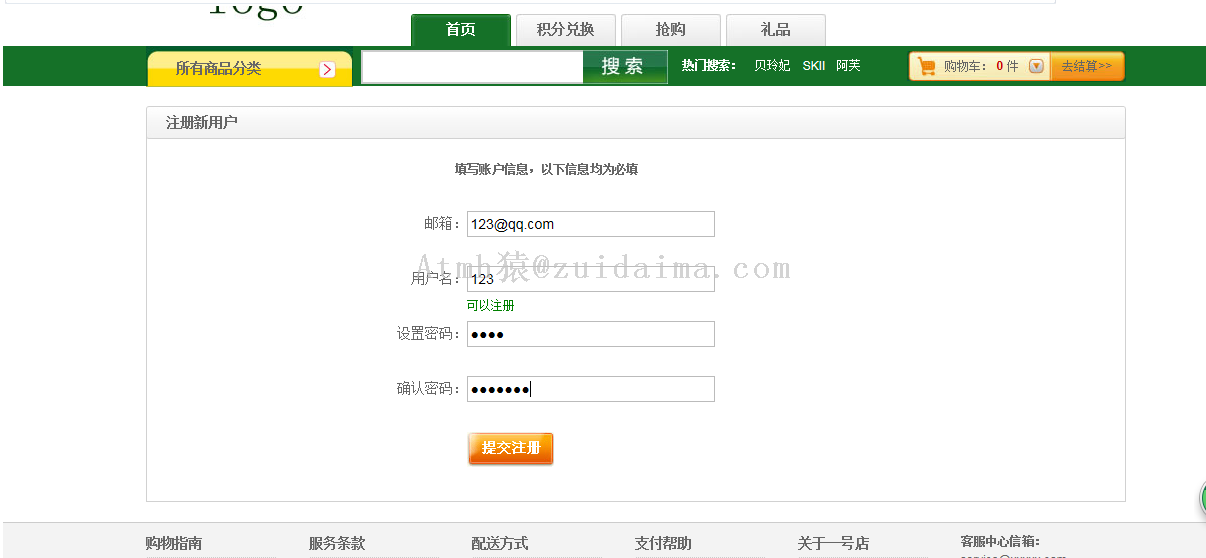
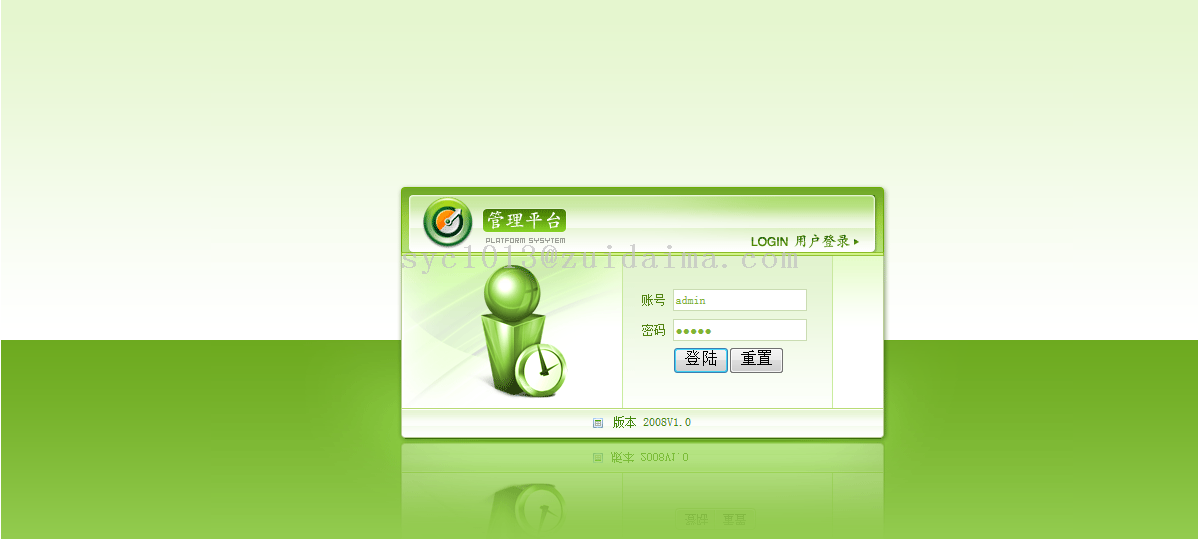
运行环境 jdk7 tomcat7 mysql数据库脚本链接: https://pan.baidu.com/s/1wxAuO7QKOsrDfOlVxfxHwg 密码: jur7运行截图1.进行注册http://localhost:8080/register.jsp2.后台,账号密码都为admin注意...


diaodiaofly LV21
2013年11月5日
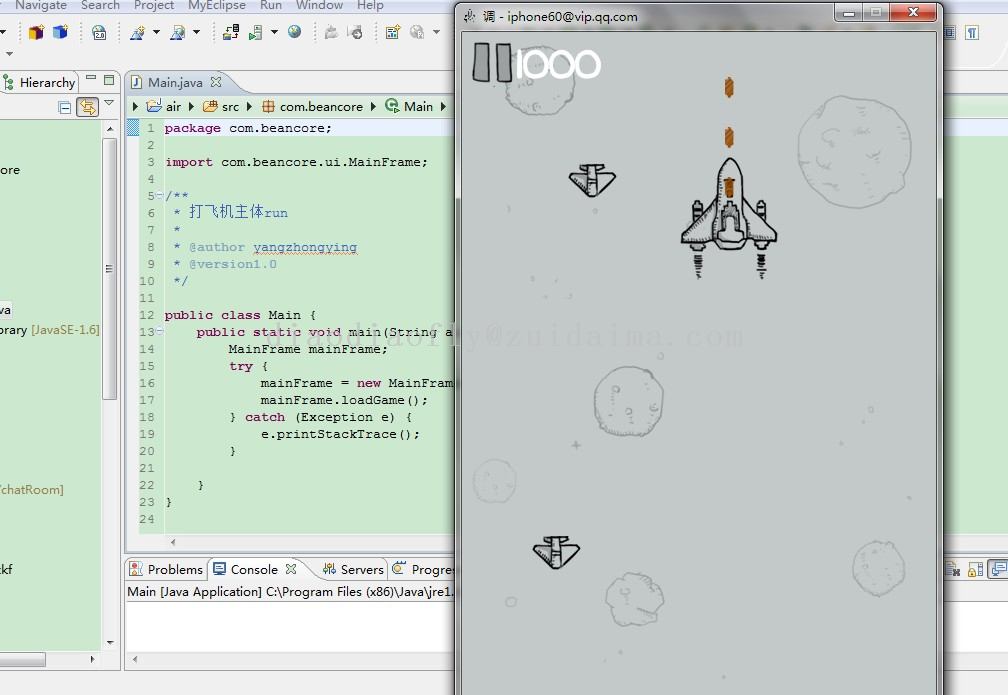
运行效果图由最代码官方编辑于2014-10-14 22:03:56...

javaboy2012 LV8
2013年1月20日
代码结构:由AXIN编辑于2014-2-22 13:10:03...

longbadx LV9
2012年9月28日
在网上看到的写的还不错!!!由Wood编辑于2013-12-25 21:37:46...
玫瑰感觉 LV23
2015年7月3日
项目描述完全是自己一个人写的,是使用mvc架构,用到Java的高级部分,servlet+jsp+pojo,jquery+ajax+jackson,threadlocal+filter,数据库的多表操作,上次上传了一个不完整的版本,没有业务操作,这次补充一下。没有使用框架,自写后台框架运行环境jdk7...
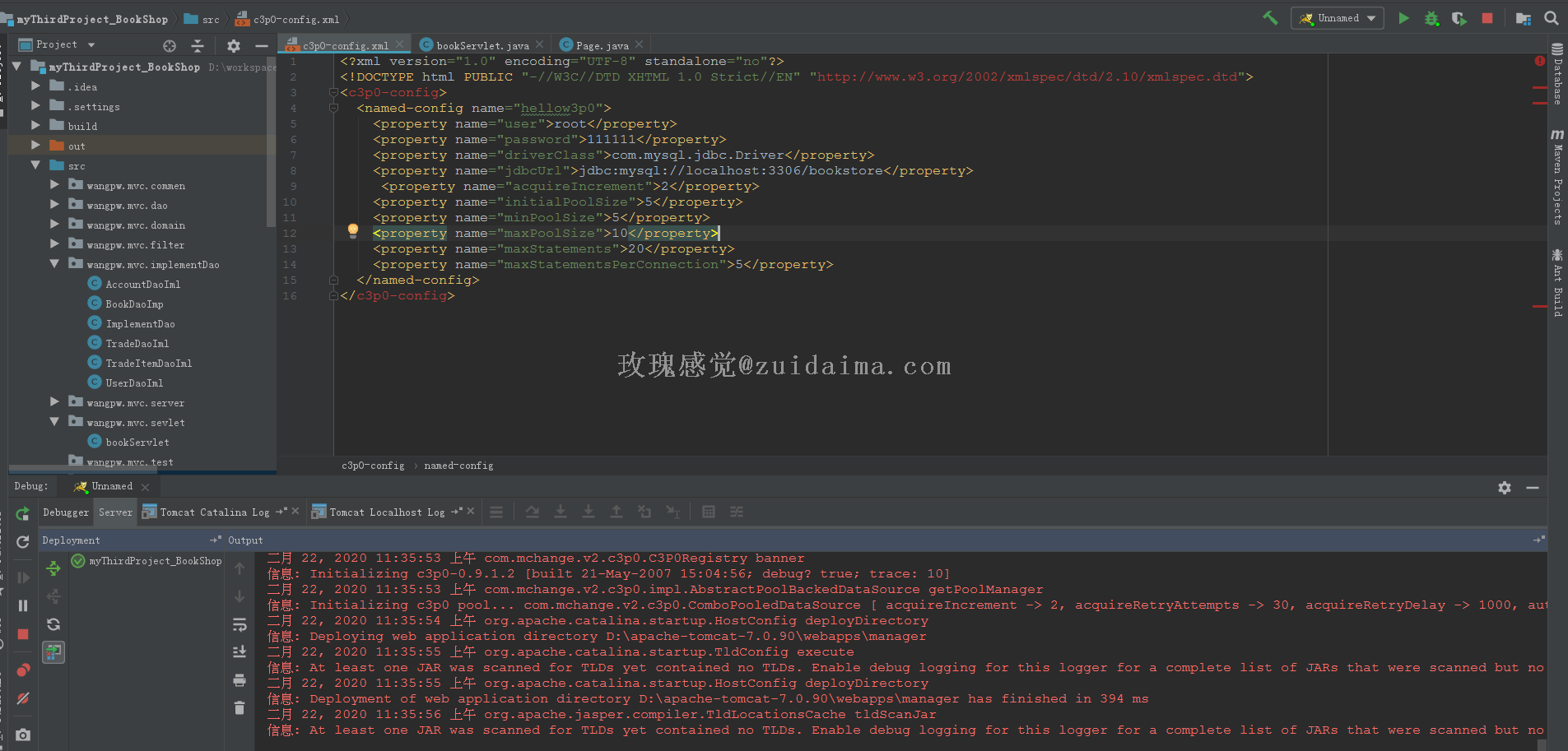

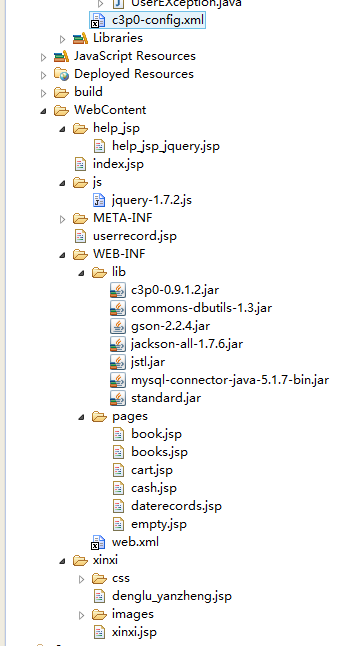

lypspy LV6
2012年10月22日
深入浅出Struts2源码由骑着猪猪去逛街编辑于2014-1-7 15:47:32...

tohigher LV3
2013年5月20日
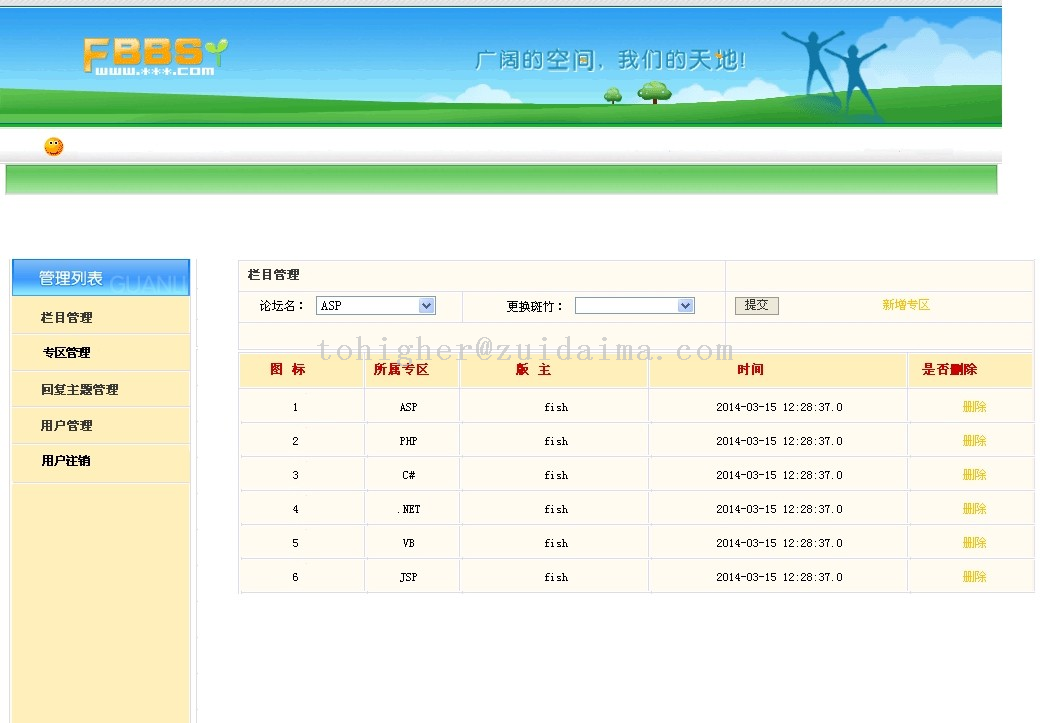
jsp+struts论坛源码。首页http://localhost:端口/项目名/index.do注册http://localhost:端口/项目名/register.do后台管理项目截图:db截图jar包截图原项目中缺少的jar包:struts.jar commons-beanutils.jar ...

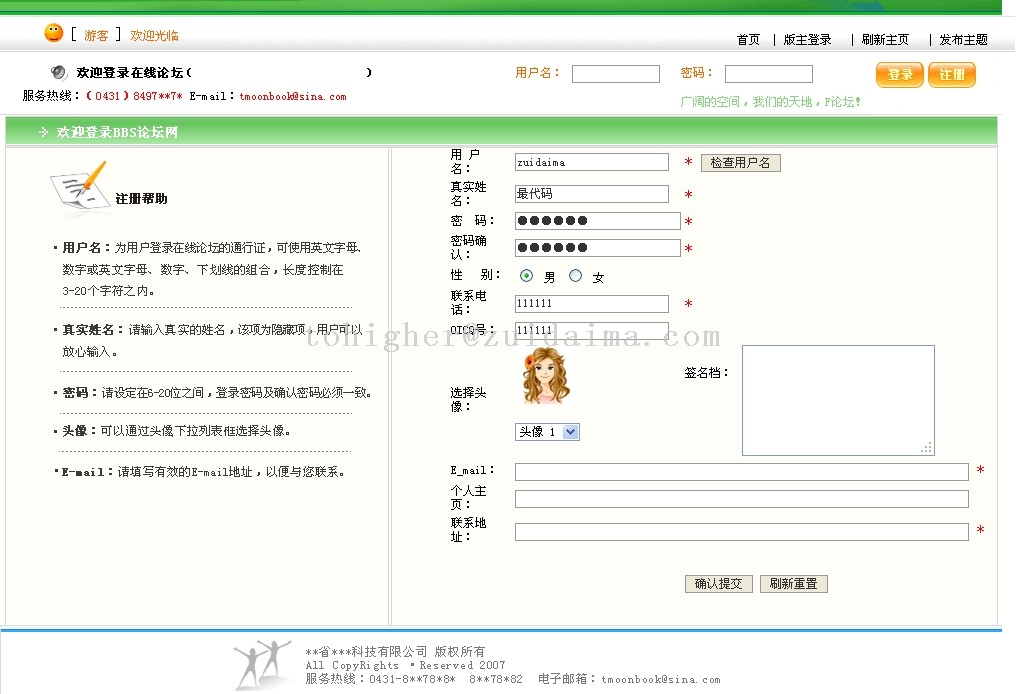

lypspy LV6
2012年10月22日
精通hibernate源码由骑着猪猪去逛街编辑于2014-1-7 15:47:01...

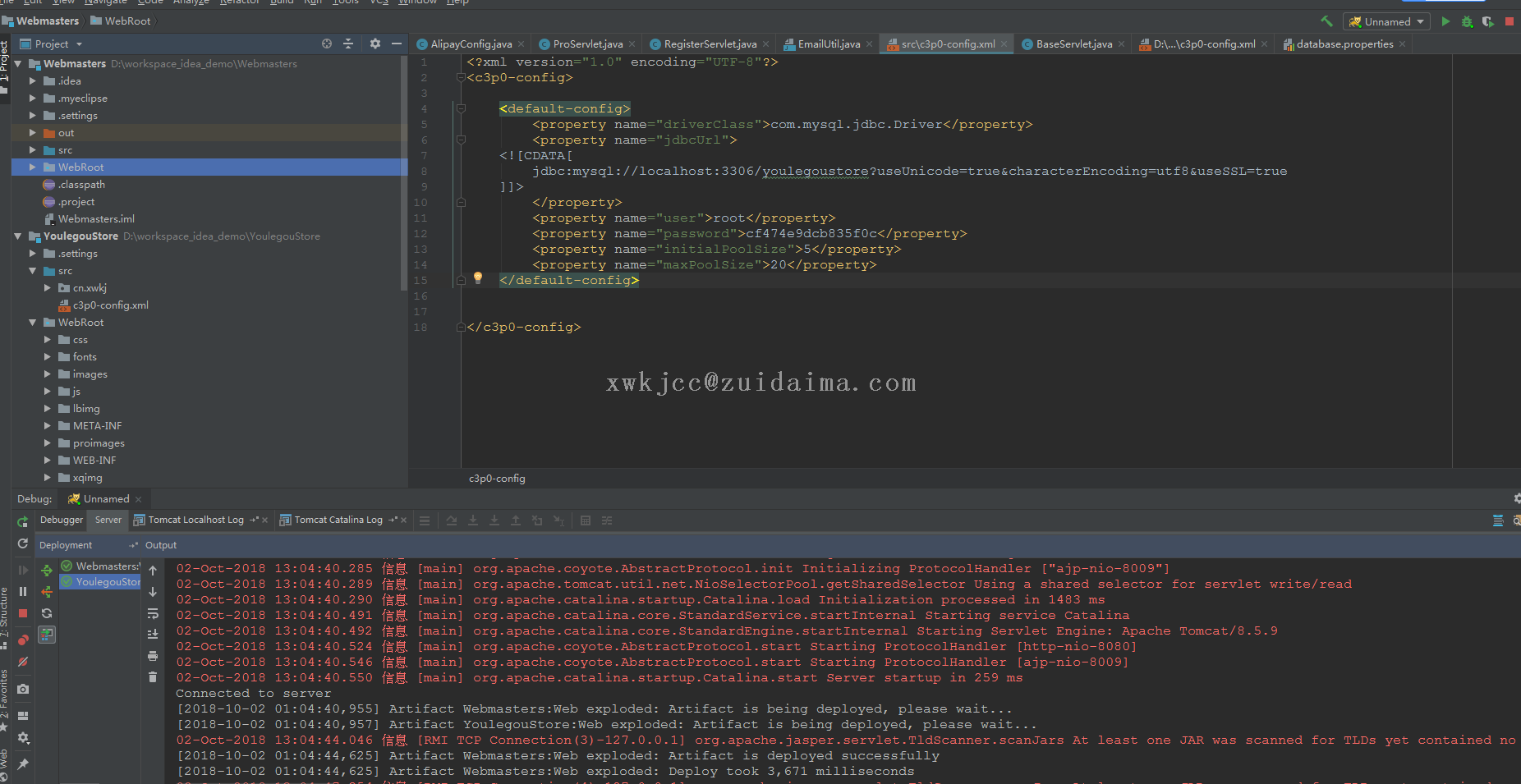
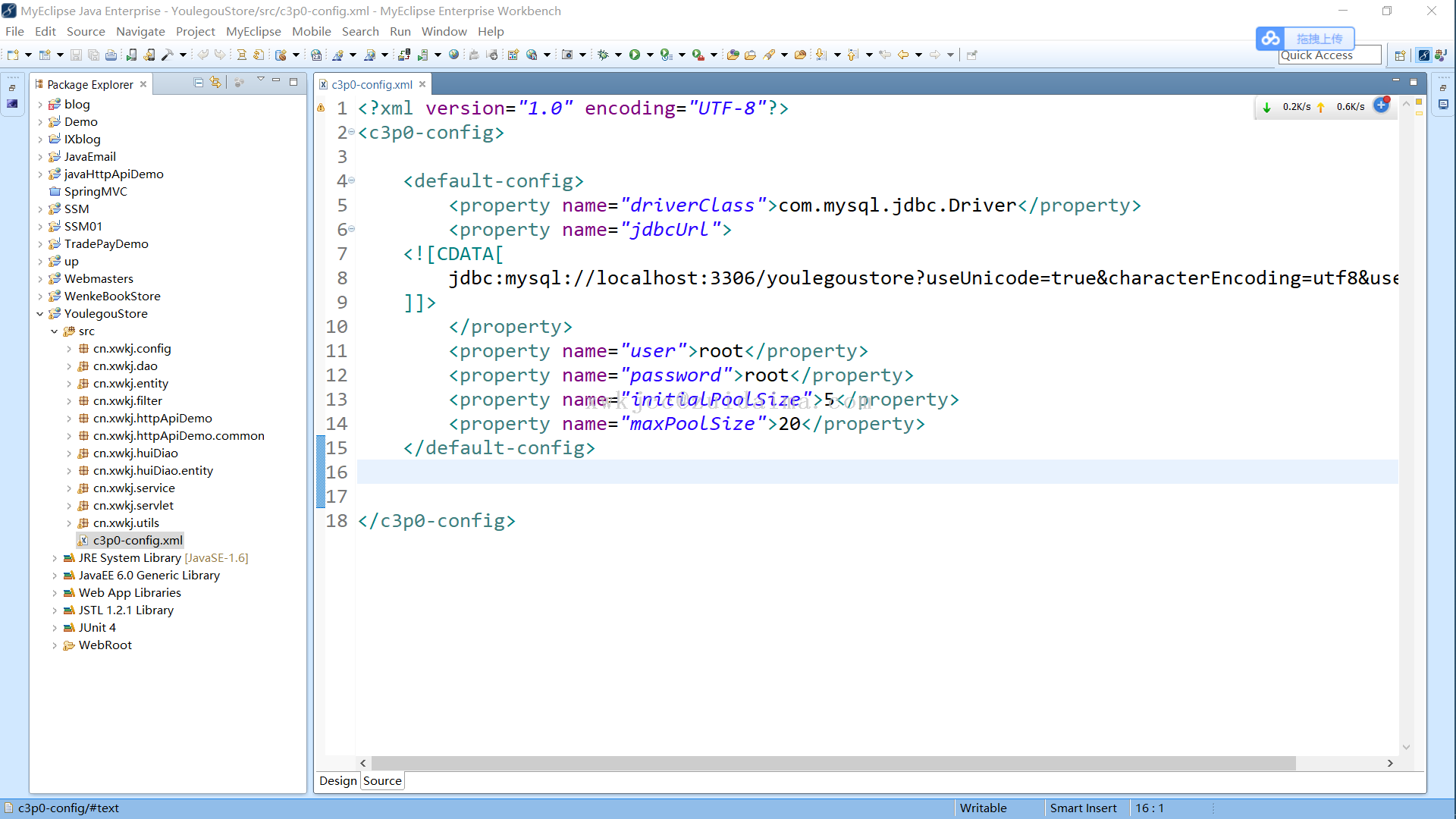
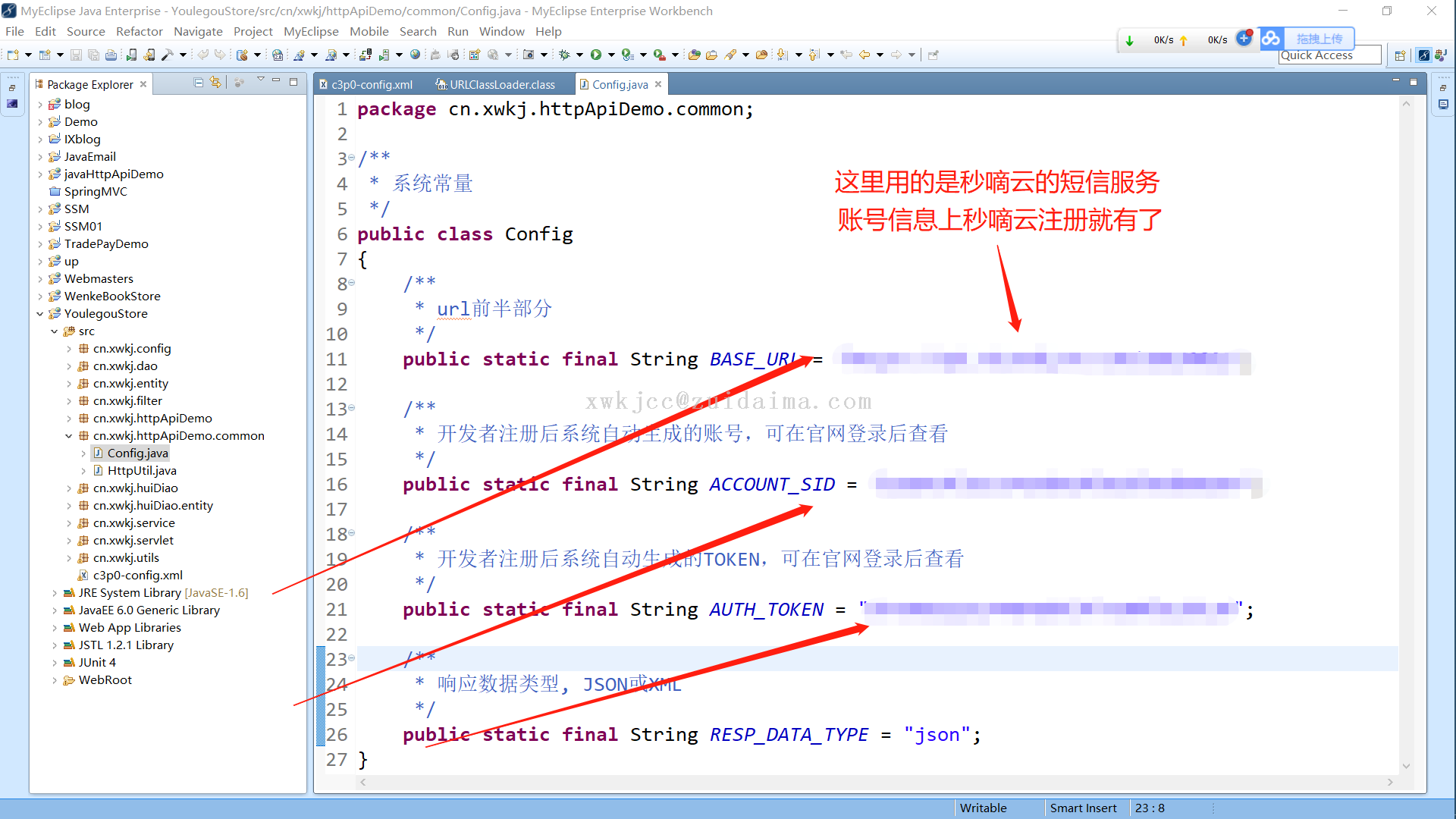

最代码-ian LV26
2017年1月13日
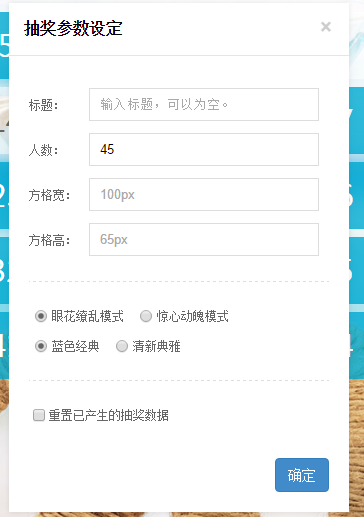
1.主页面,挺好看的,在别人家里面找的个,根据自己的需求改的,按A或者空格键开始,结束也是一样的。2.在有点高级shezh 里面可以根据自己的需求设置人数以及高宽这些东西,以及重置这些3.抽奖成功后就是这样子的了4.给大家一个测试的地方呀http://cj.yunhui818.com原作者源码地址:...